
![]() Для мониторинга контейнерной нагрузки используется cAdvisor. Одной из основных системных метрия является Container CPU usage и именно с ней у cAdvisor не все так просто. В статье подробно разберем каким образом рассчитать реальную нагрузку CPU.
Для мониторинга контейнерной нагрузки используется cAdvisor. Одной из основных системных метрия является Container CPU usage и именно с ней у cAdvisor не все так просто. В статье подробно разберем каким образом рассчитать реальную нагрузку CPU.
Содержание
Container CPU usage
Все метрики, которые отдает cAdvisor, вы можете найти в документации официального репозитория 1. Нас интересуют только CPU и только 3 метрики, вот они:
- container_cpu_usage_seconds_total
- container_cpu_user_seconds_total
- container_cpu_system_seconds_total
Рассмотрим каждую из них подробно.
container_cpu_usage_seconds_total
Метрика container_cpu_usage_seconds_total отображает не только загрузку ЦПУ контейнеров, которую вы можете отфильтровать лейблом {name!=»»}. Эта метрика также показывает потребление ЦПУ другими процессами в системе, отображая суммарное потребление в метрике с лейблом {id=»/»}. Кроме того, делает она это по каждому ядру (см. лейбл cpu). Итак, чтобы получить динамику средней загрузки по всем ядрам, нужно, во-первых, взять функцию rate(), поскольку метрика представляет из себя счетчик.
Во-вторых, от полученного ряда берем среднее значение, исключив лейбл cpu:
|
1 |
avg(rate(container_cpu_usage_seconds_total{name!=""}[5m]))without(cpu) |
Полученные значения представляют из себя усредненное в пересчете на ядро время, которое ЦПУ затратил на выполнение задач каждого контейнера. Как теперь его перевести в проценты? Предположим, что за 100% мы принимаем 1 секунду, а значит просто делим наше значение на единицу и умножаем на 100:
|
1 |
avg(rate(container_cpu_usage_seconds_total{name!=""}[5m]))without(cpu) / 1 * 100 |
Итого данная метрика покажет нам на сколько процентов грузит ЦПУ каждый контейнер.
container_cpu_system_seconds_total & container_cpu_user_seconds_total
Помимо container_cpu_usage_seconds_total есть также и другие метрики, которые показывают system и user cpu time по каждому контейнеру — container_cpu_system_seconds_total и container_cpu_user_seconds_total соответственно . Применить ту же логику к ним не получится, потому что у них нет лейбла cpu. Также, если вы посмотрите на сумму этих метрик, то она будет значительно больше cpu usage из предыдущей главы, что само по себе странно, потому что должна быть примерно равна ему. Можно предположить, что отсутствие лейбла cpu намекает на то, что system и user cpu time отображают время по всем ядрам в сумме. В таком случае надо просто разделить их на количество ядер, которое мы можем просто посчитать по каждому контейнеру следующим выражением:
|
1 |
count(container_cpu_usage_seconds_total{name!=""})without(cpu) |
Итого получаем выражения:
|
1 2 |
rate(container_cpu_user_seconds_total{name!=""}[5m]) / count(container_cpu_usage_seconds_total{name!=""})without(cpu) * 100 rate(container_cpu_system_seconds_total{name!=""}[5m]) / count(container_cpu_usage_seconds_total{name!=""})without(cpu) * 100 |
Сумма (зеленая кривая) этих метрик как раз будет приблизительно равна выражению из прошлой главы:
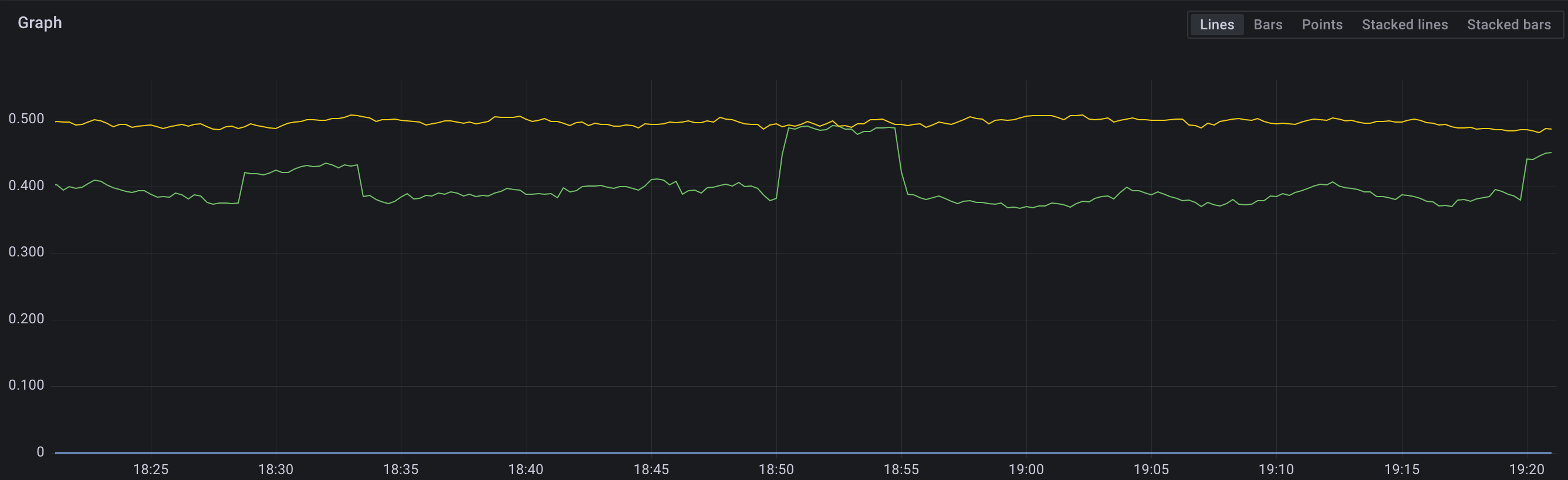
Как видно, точного равенстве не получилось, но это и нормально, потому что кроме user и system time вообще-то есть и другие режимы работы ЦПУ (например iowait, steal time и пр.).
Как проверить себя?
Хочется быть уверенным в полученных расчетах, а потому было бы неплохо проверить себя. Есть как минимум несколько способов сделать это.
Вариант 1
Поскольку метрика container_cpu_usage_seconds_total{id=»/»} отдает итоговую загрузку ЦПУ вообще всеми процессами в системе, значит её данные можно сравнить с показателями метрики cpu time от node_exporter — node_cpu_seconds_total. Это тоже счетчик, а потому сразу берем rate():
|
1 |
rate(node_cpu_seconds_total[5m]) |
Вы заметите, что она также показывает время ЦПУ по ядрам, а значит берем от них среднее:
|
1 |
avg(rate(node_cpu_seconds_total[5m]))without(cpu) |
Метрика также отображает время бездействия — {mode=»idle»} — которое равно сумме остальных режимов работы ЦПУ, вычтенных из 100, а потому idle надо просто исключить из наших результатов. Убираем idle и берем сумму значений оставшихся режимов. Ну и напоследок также делим на единицу и умножаем на 100, чтобы получить процент:
|
1 |
sum(avg(rate(node_cpu_seconds_total{mode!="idle"}[5m]))without(cpu))without(mode) / 1 * 100 |
Сравните теперь её с метрикой из первой главы (container_cpu_usage_seconds_total желтого цвета):
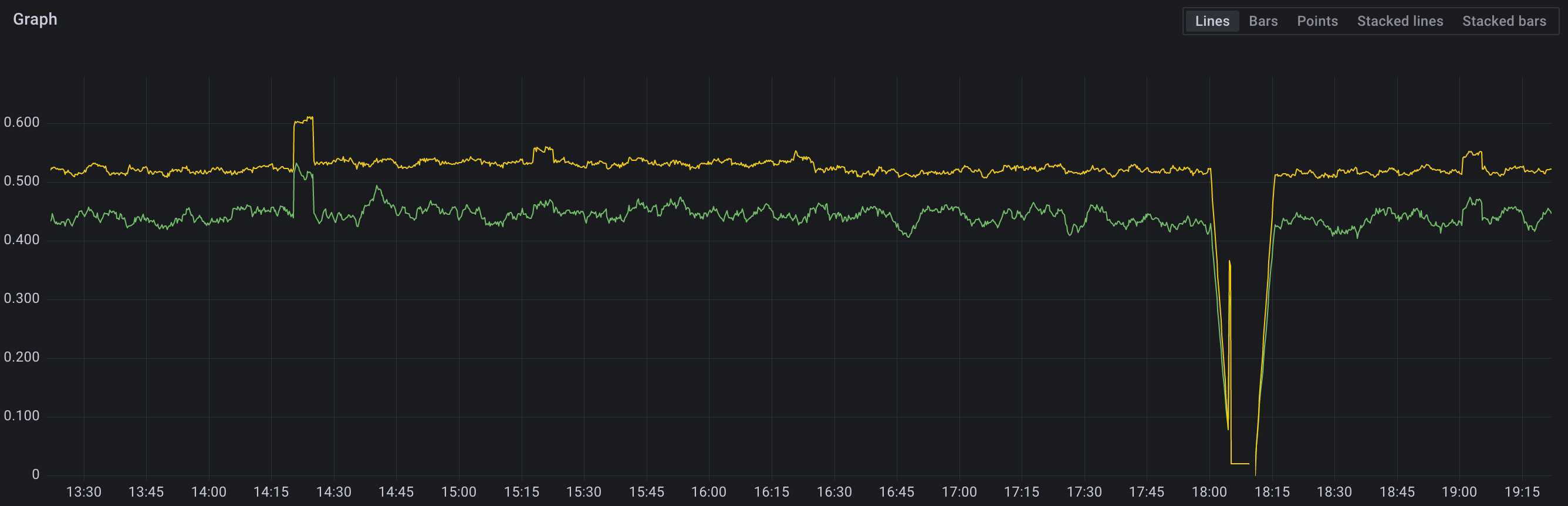
Значения могут отличаться по многим причинам — разное время сбора метрик Прометеем, различия в методиках подсчета, погрешности и прочее. Тем не менее разница должна составлять лишь небольшие проценты, но не быть многократной (на изображении выше разница не больше одной десятой процента).
Вариант 2
Можно сравнить и по другой методике. Мы знаем, что сумма времени работы ЦПУ во всех режимах в пересчете на ядро будет равна 1 секунде/сек (очевидно), то есть 100%. Но на всякий случай убедиться в этом вы можете с помощью следующей формулы (ноль обозначен для наглядности горизонтальной линией):
|
1 |
sum(avg(rate(node_cpu_seconds_total[5m]))without(cpu))without(mode) |
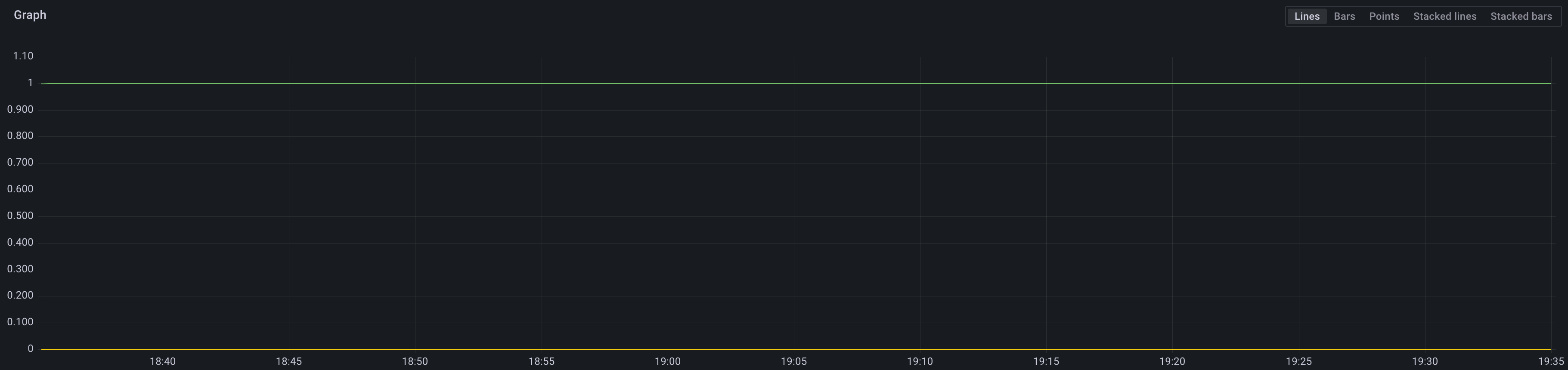
Идем далее. Нам нужно получить среднее значение времени ЦПУ по всем ядрам, а потому возьмем сумму по всем режимам работы, кроме idle и умножим на 100:
|
1 |
sum(avg(rate(node_cpu_seconds_total{mode!="idle"}[5m]))without(cpu))without(mode) * 100 |
В итоге получаем идентичную картину:
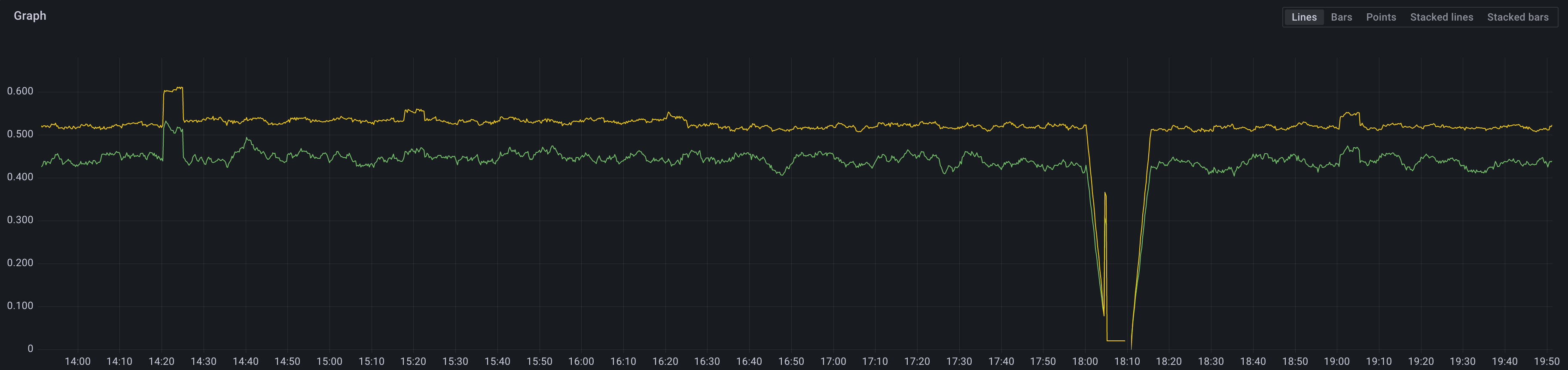
Итого корректность результатов проверена двумя разными способами.
Исключения
В рассуждениях выше я отталкивался от того, что максимальная нагрузка на ЦПУ равна 100% или, если нужно перевести во время, составляет одну секунду/сек в пересчете на ядро. Тем не менее вероятно вы встретитесь с ситуациями, когда нагрузка будет явно выше 100%, почему?
- Одной из причиной могут являться режимы увеличения производительности ЦПУ путем повышения тактовой частоты. У Intell это называется Turbo Boost;
- Еще один случай, более тонкий и интересный, это производительность ЦПУ в облаке. Облачные провайдеры обычно предоставляют кредиты для кратковременного увеличения производительности процессора до момента, когда эти самые кредиты будут исчерпаны. Объем кредитов зависит от стоимости самого инстанса — чем он мощнее, тем больше кредитов. Выражается это в дополнительных секундах работы ЦПУ. Вот яркий пример:
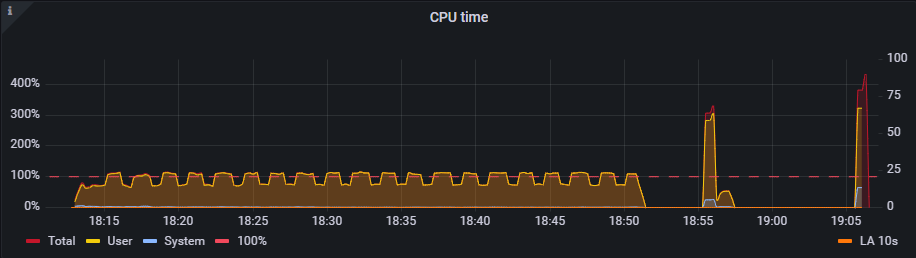 Примечание: сначала гипервизор тротлил ЦПУ, потом было кратковременное падение нагрузки до нуля и видимо за этот период кредиты восстановились. Именно поэтому потом виден всплеск аж до 300%, но дополнительное процессорное время выжралось достаточно быстро.
Примечание: сначала гипервизор тротлил ЦПУ, потом было кратковременное падение нагрузки до нуля и видимо за этот период кредиты восстановились. Именно поэтому потом виден всплеск аж до 300%, но дополнительное процессорное время выжралось достаточно быстро.
На этом все. Если вдруг у вас будут другие мысли или вы найдете ошибку в моих рассуждениях, обязательно напишите в комментариях, спасибо!


