
![]() Горячая замена диска Adaptec 6405 официально поддерживается RAID-контроллером и осуществляется достаточно просто. При этом вам все же лучше будет полностью протестировать этот процесс пока сервер ещё не введен в работу, а также задокументировать эти шаги. Если какой-либо диск (или несколько дисков) все же выйдут из строя на массиве с полезной нагрузкой, вам будет не до выяснения нюансов работы контроллера, нужно будет выполнять замену диска и лучше, чтобы вы были полностью уверены в этом процессе. Для тех, кто поленился сделать для себя подробный гайд step by step главным образом и предназначается эта статья (ну а также разумеется для меня самого и моих коллег).
Горячая замена диска Adaptec 6405 официально поддерживается RAID-контроллером и осуществляется достаточно просто. При этом вам все же лучше будет полностью протестировать этот процесс пока сервер ещё не введен в работу, а также задокументировать эти шаги. Если какой-либо диск (или несколько дисков) все же выйдут из строя на массиве с полезной нагрузкой, вам будет не до выяснения нюансов работы контроллера, нужно будет выполнять замену диска и лучше, чтобы вы были полностью уверены в этом процессе. Для тех, кто поленился сделать для себя подробный гайд step by step главным образом и предназначается эта статья (ну а также разумеется для меня самого и моих коллег).
Подробнее о контроллерах Adaptec серии 6xxx читайте в головной статье — RAID-контроллер Adaptec 6405.
Если вам интересны raid-технологии и задачи администрирования raid-контроллеров, рекомендую обратиться к рубрике RAID на моем блоге.
Горячая замена диска Adaptec 6405
Для начала нужно определить в какой корзине находится диск, который нам нужно заменить. Есть несколько способов это сделать:
1) При должной настройке диск скорее всего сидит в корзине с тем порядковым номером, в какой и должен (судя по информации из ASM. Учтите, что номера корзин начинаются с 0);
2) На всякий случай можно подстраховаться и точно определить корзину. Для этого в утилите Adaptec Storage Manager нажимаем правой кнопкой на нужном диске — Blink physical disk.
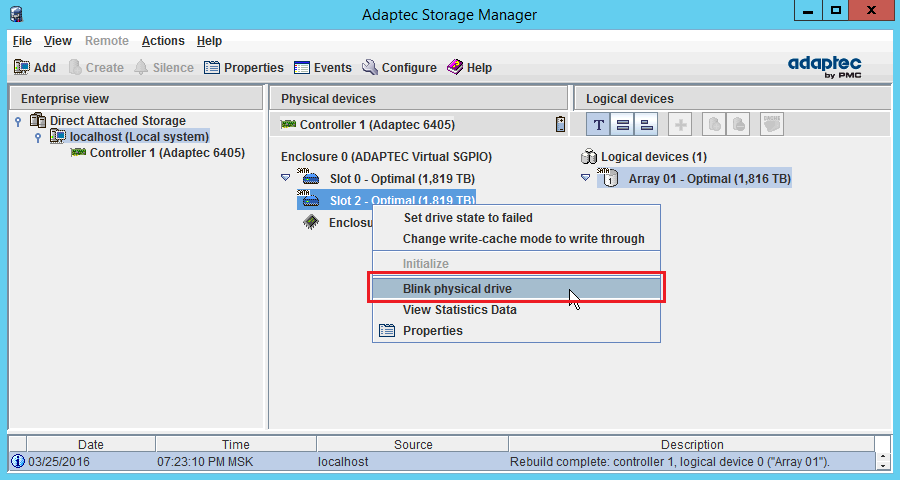
На этом моменте корзина диска должна ритмично замигать красным светодиодом.

3) Ничего не делать и просто через ASM перевести диск в состояние Failed. В этом случае контроллер начнет издавать мерзкий писк и будет непрерывно светиться красный светодиод на корзине с проблемным диском.
Отлично, допустим диск определен (или вы пропустили этот шаг), двигаемся дальше. Теперь нужно подготовить диск к изъятию. Можно конечно его просто выдернуть, но не думаю, что это хорошее решение, тем более когда все можно сделать правильно. К тому же так рекомендуют сделать и в официальной документации 1.
When removing a drive to simulate a failure or pro-actively replace a questionable drive, it is recommended to use the Storage Manager «set drive state to failed» or CLI / ARCCONF «force fail» option prior to removing the drive. When the drive is marked as failed, it is safe to remove and replace the drive.
Нажимаем правой кнопкой на нужном диске — Set drive state to failed:
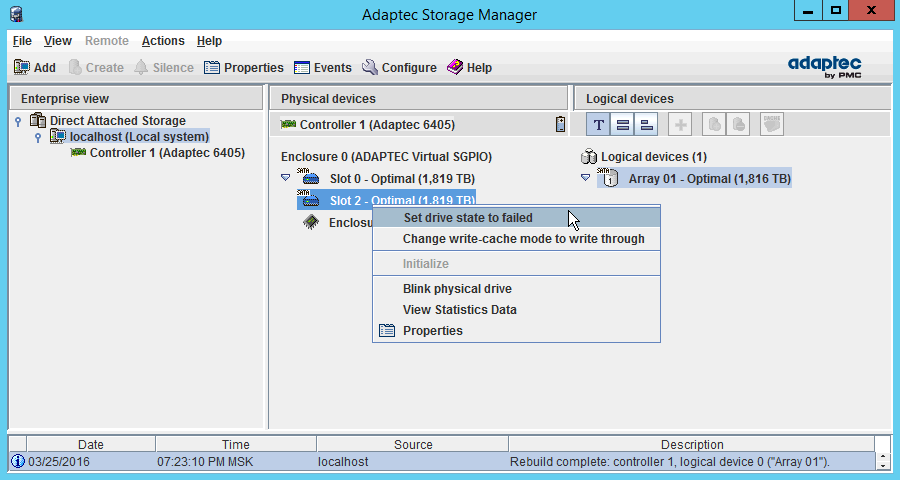
Сразу выскочит предупреждение, что массив будет переведен в деградированное состояние:
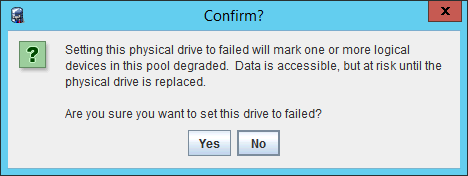
Подтверждаем. В реальной среде вышедший из строя диск скорее всего и так будет в состоянии Failed, а массив в деградированном виде. У меня же эксперимент на тестовой среде и я перевожу диск в нужное состояние вручную. Вот как изменятся показания ПО:
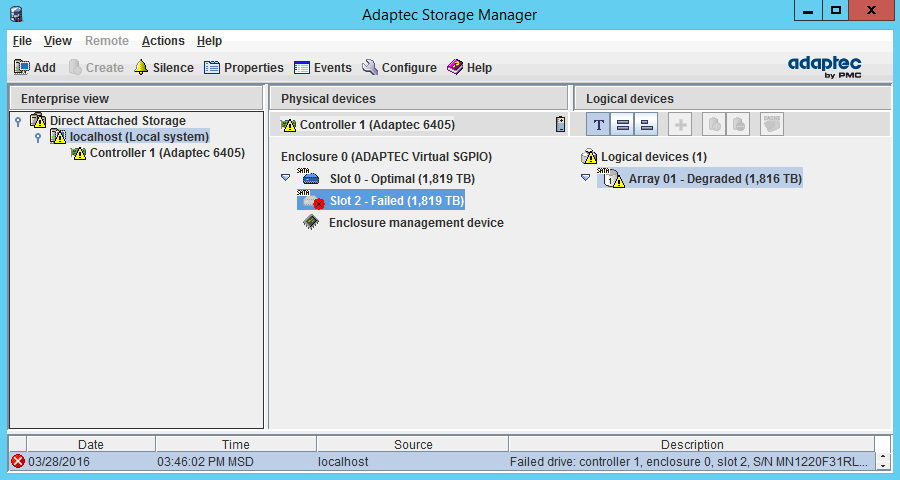
Напоминаю, что массив при этом у меня формально остался в рабочем состоянии, ведь я использую RAID1 и он обеспечивает работоспособность при выходе из строя до половины дисков.
На этом этапе можно смело идти и заменять диск на новый (объем диска вплоть до байта должен быть больше или равен объему других дисков в действующем массиве). Контроллер при этом будет издавать писк (как я и говорил выше), а корзина с проблемным диском сигнализировать о проблеме непрерывно горящим красным светодиодом.
После замены показания ASM будут выглядеть следующим образом:
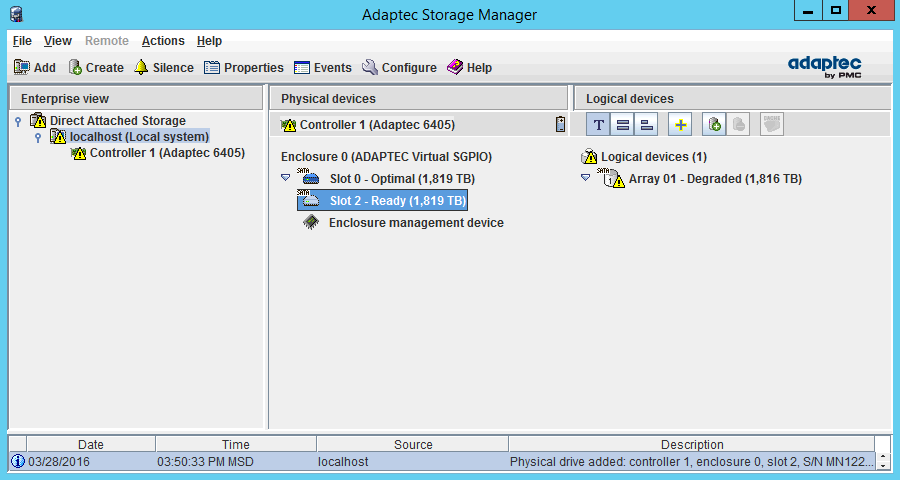
Новый диск готов к использованию и нужно его инициализировать. Нажимаем правой кнопкой на диске — Initialize:
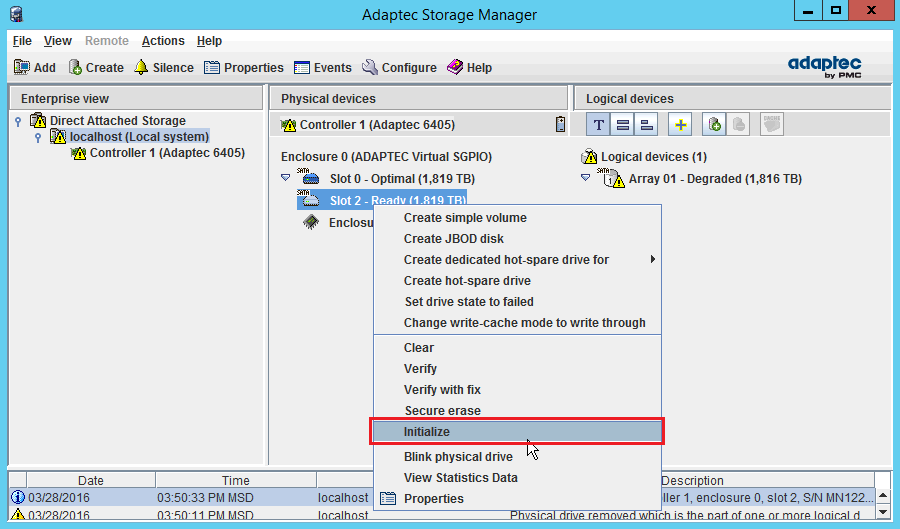
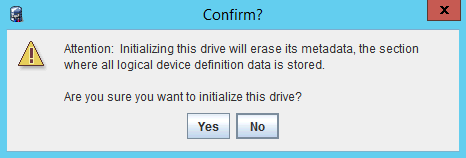
Получаем предупреждение и соглашаемся с ним:
Далее нужно дать понять контроллеру, что он может использовать новый диск вместо недавно «вышедшего из строя» и замененного диска. Для этого нужно сделать новый диск диском горячей замены (правой кнопкой на новом диске — Create dedicated hot-spare drive for):
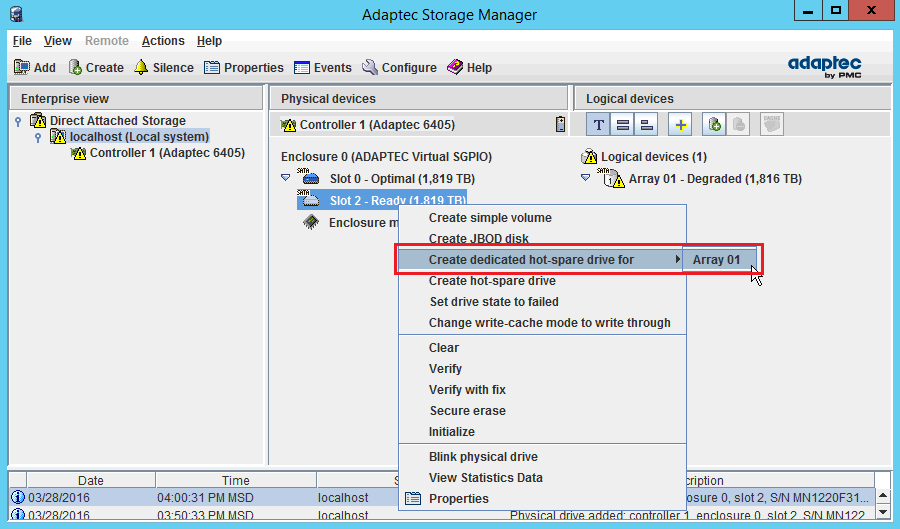
Никаких дополнительных диалоговых окон выскочить не должно, а диск сразу станет частью массива:
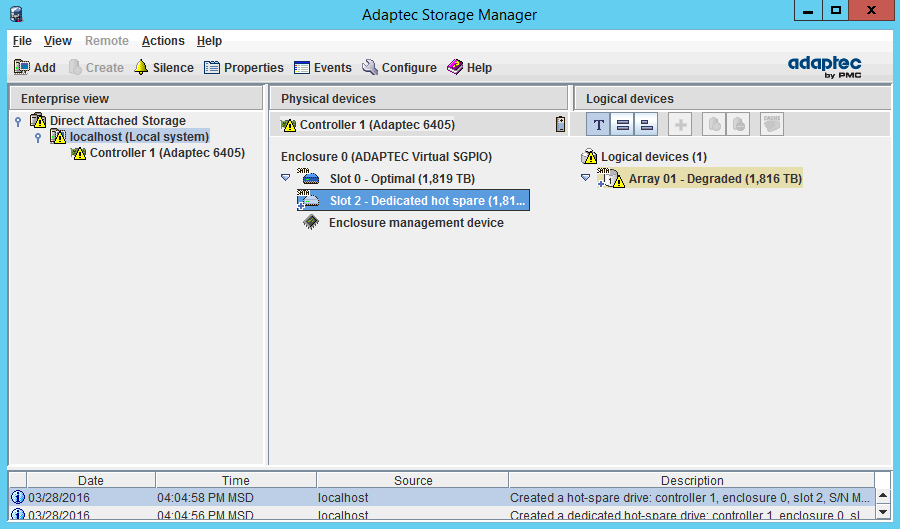
и автоматически запустится процесс ребилда:
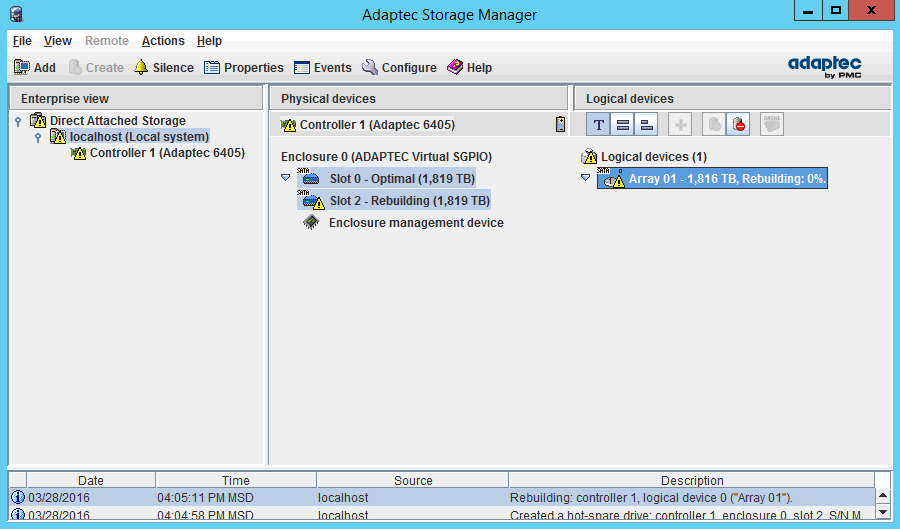
Во время процесса работа сервера может не прекращаться (для наглядности скриншоты ASM я снимал как раз с того же сервера, на котором проводил тестирование). Только учтите один момент: ребилд — достаточно ресурсоемкий процесс и если в вашем массиве небольшое количество низкопроизводительных дисков (а сейчас это фактически любые диски, кроме SSD), то лучше провести технические обслуживание, предварительно сняв полезную нагрузку с сервера. Это особенно касается массивов RAID5 (и им подобных), которые в продакшене вообще использовать не рекомендуется (почему, читайте подробнее в моей статье — Типы RAID-массивов).
