
![]() Представляю вашему вниманию вторую статью из серии, посвященной процессу записи данных в СУБД Cassandra. В этот раз я планирую представить информацию о следующем компоненте – промежуточном кэше данных колоночных семейств.
Представляю вашему вниманию вторую статью из серии, посвященной процессу записи данных в СУБД Cassandra. В этот раз я планирую представить информацию о следующем компоненте – промежуточном кэше данных колоночных семейств.
Сразу же после помещения данных в Commit Log, информация также дублируется в структуру, называемую Memtable. Этот компонент имеет следующие свойства:
- Элементы, хранящиеся в Memtable, отсортированы по ключам записей;
- Данные внутри записей отсортированы по колонкам;
- Для поиска и вставки элементов используется алгоритм Java ConcurrentSkipListMap;
- Для каждого колоночного семейства существует отдельная MemTable (в английской терминологии Memtable описывается как per-ColumnFamily structure 1).
Теперь рассмотрим все подробнее. Чтобы лучше понять структуру Memtable, дополним иллюстрации из первой части обзора (Apache Cassandra. Запись данных. Часть 1 – Commit Log). Напомню, что изображения созданы на подобии иллюстраций из официальной документации 2.
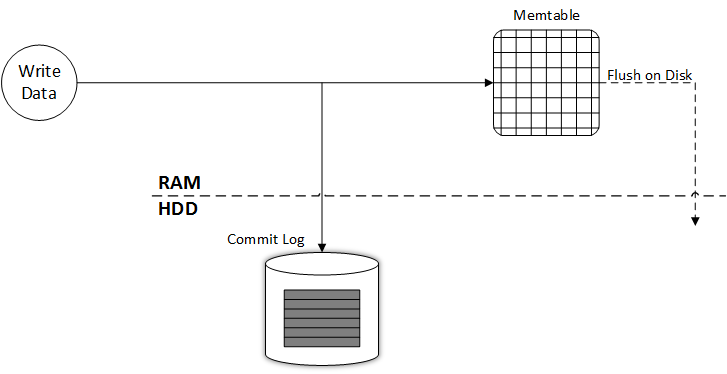 Принцип работы: процесс записи данных начинается с логирования всех операций в Commit Log, это необходимо для восстановления в случае сбоя работы узла. Сразу после этого данные дублируются в Memtable. Однако Memtable не осуществляет логирование, то есть точное запоминание вообще всех операций, а только хранит самые свежие данные. Это вполне логично с той точки зрения, что место в оперативной памяти значительно дороже, чем место на жестком диске. Исходя из того, что данные в Memtable упорядочены по ключу записи, а внутри ключа по колонкам, то наш рисунок можно усложнить соответствующим образом. Возьмем расширенный вариант схемы также из предыдущей части обзора процесса записи данных:
Принцип работы: процесс записи данных начинается с логирования всех операций в Commit Log, это необходимо для восстановления в случае сбоя работы узла. Сразу после этого данные дублируются в Memtable. Однако Memtable не осуществляет логирование, то есть точное запоминание вообще всех операций, а только хранит самые свежие данные. Это вполне логично с той точки зрения, что место в оперативной памяти значительно дороже, чем место на жестком диске. Исходя из того, что данные в Memtable упорядочены по ключу записи, а внутри ключа по колонкам, то наш рисунок можно усложнить соответствующим образом. Возьмем расширенный вариант схемы также из предыдущей части обзора процесса записи данных:

Нужны небольшие пояснения – поскольку для каждого колоночного семейства существует отдельная структура данных Memtable, соответственно маркировка CF означает Column Family. Внутри каждого CF данные упорядочены по ключу записи. Column Data означает полезные данные, представленные в виде колонок. Различная длина сегментов данных обусловлена тем, что количество и объем колонок внутри записи может значительно отличаться даже в рамках одного колоночного семейства. Эту особенность архитектуры я подробно описал в статье Apache Cassandra. Первичные ключи и особенности хранения записей.
Для поиска и вставки новых элементов в Memtable используется алгоритм Skip List 3, вернее его реализация на Java – ConcurrentSkipListMap 4 5. Понимание принципа его работы не совсем обязательно в контексте изучения Memtable, однако этот алгоритм делает и без того быстрый поиск по оперативной памяти ещё быстрее и поэтому я вкратце постараюсь объяснить его основы.
Принцип работы алгоритма состоит в создании нескольких уровней с данными. На первом уровне находится список всех упорядоченных по возрастанию ключей. С определенной вероятностью какое-либо значение с первого уровня может быть продублировано на второй уровень. Значения со второго уровня также с некоторой вероятностью могут быть продублированы на уровень выше и так далее. Пропуски не допускаются – например, нельзя чтобы значение было на первом и третьем уровне, а на втором отсутствовало. При поиске элементов обращение сначала идет к самому высокому уровню, первое встретившееся значение сравнивается с искомым и если оно не равно ему, то спускаемся на уровень ниже и в зависимости от того меньше текущее значение искомого или больше, поиск идет в сторону убывания или возрастания элементов соответственно. Лучше всего этот процесс показывает анимация (кликните для просмотра) из статьи на Википедии 6:
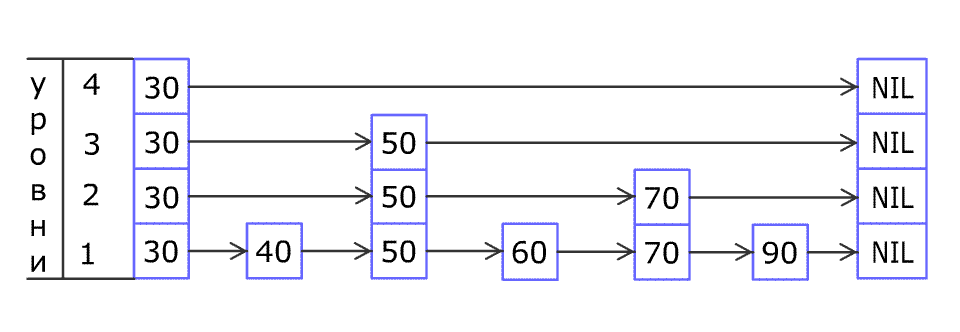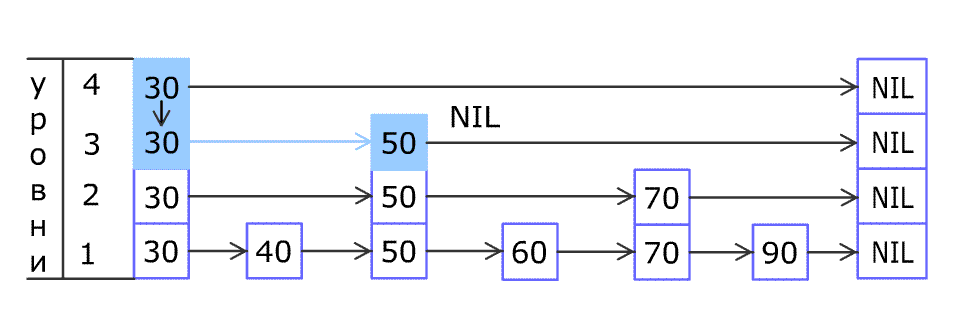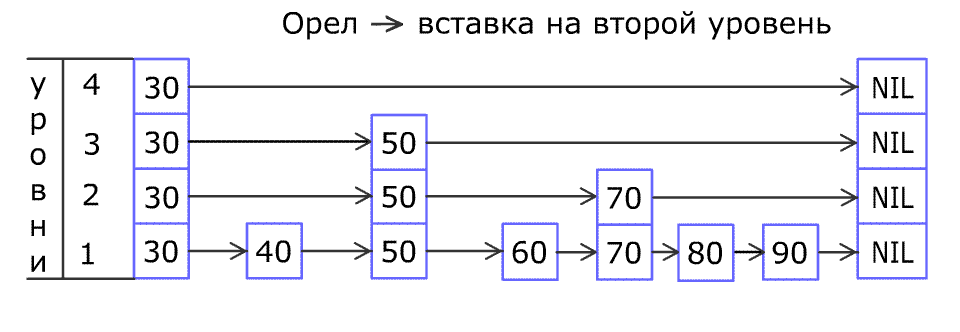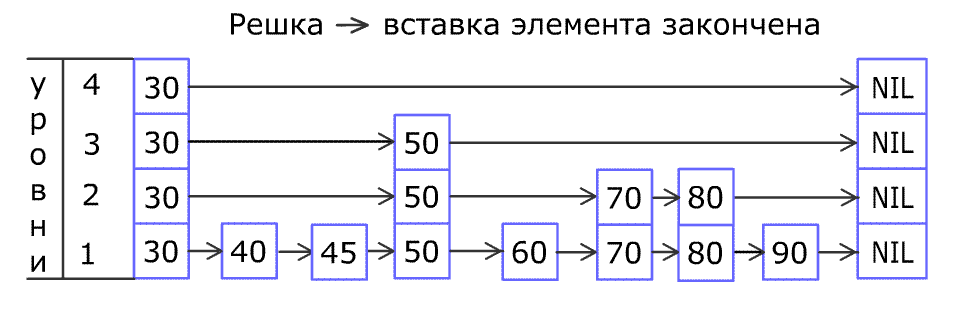
Более подробно рассмотреть алгоритм по шагам можно в статье на Хабре 7 и некоторых других источниках 8, а мы идем дальше.
К данным, находящимся в Memtable, впоследствии можно получать доступ как к кэшу при клиентских запросах чтения. Это также одно из отличий от Commit Log, к которому не могут осуществляться клиентские запросы.
Когда Memtable достигает определенного объема, происходит сброс (flush) данных в структуру, называемую SSTable, которая располагается на жестком диске. Регулировать максимальный объем Memtable можно с помощью параметра memtable_total_space_in_mb, который по умолчанию с версии Cassandra 2.0.2 9 стал равен четверти (ранее треть) от объема памяти, выделяемой для динамической памяти Java (Java heap size).
В свою очередь управление памятью Java осуществляет Cassandra самостоятельно и в зависимости от объема RAM устанавливаются следующие значения 10:
| RAM | Heap Size |
|---|---|
| Менее 2GB | 1/2 RAM |
| От 2GB до 4GB | 1GB |
| Более 4GB | 1/4 RAM, но не более 8GB |
Выставлять объем более 8ГБ не рекомендуют в виду возрастающих до критического уровня расходов на задачи обслуживания (таких как garbage collection), а также появления возможности влияния на процессы операционной системы:
Many users new to Cassandra are tempted to turn up Java heap size too high, which consumes the majority of the underlying system’s RAM. In most cases, increasing the Java heap size is actually detrimental for these reasons:
– In most cases, the capability of Java to gracefully handle garbage collection above 8GB quickly diminishes.
– Modern operating systems maintain the OS page cache for frequently accessed data and are very good at keeping this data in memory, but can be prevented from doing its job by an elevated Java heap size.
If you have more than 2GB of system memory, which is typical, keep the size of the Java heap relatively small to allow more memory for the page cache.
Следующий параметр, отвечающий за работу Memtable – file_cache_size_in_mb. Судя по описанию в официальной документации, используется как промежуточный кэш для чтения данных (SSTable-reading buffer) перед их записью в SSTable.
Осуществлять гибкое управление Memtable можно с помощью параметров memtable_flush_writers 11 и memtable_flush_queue_size 12. Первый параметр отражает количество (от 2 до 8 по умолчанию) экземпляров процесса, отвечающего за сброс данных на жесткий диск. Если у вас множество каталогов данных, большой размер Java heap или в в процессе перемещения данных из Memtable на HDD участвует множество жестких дисков, рекомендуется увеличить это значение и таким образом распараллелить процесс. Это актуально также при использовании SSD. Второй параметр задает максимальное количество полных Memtable, ожидающих сброса на жесткий диск. Его рекомендуют устанавливать в значение, которое равно максимальному количеству индексов какого-либо колоночного семейства. Эта рекомендация связана с особенность хранения индексов: индекс для колоночного семейства – это фактически ещё одно колоночное семейство, ключом которого является индексное поле оригинального CF 13:
At the storage layer, a secondary index is simply another column family, where the key is the value of the indexed column, and the columns contain the row keys of the indexed table…
…Cassandra co-locates index entries with their associated original table keys.
Стоит отдельно рассмотреть изменения касательно Memtable, которые были введены в версии Cassandra 2.1 14. Если до этой версии Memtable располагались исключительно в Java heap, то теперь можно переместить буфер Memtable в собственную память Cassandra. В связи с этим были добавлены соответствующие переменные в параметры конфигурации. Параметр memtable_allocation_type определяет три 15 новых значения (первое я пропущу, поскольку оно соответствует типу хранения до версии 2.1) 16:
– offheap_buffers moves the cell name and value to DirectBuffer objects. This has the lowest impact on reads — the values are still “live” Java buffers — but only reduces heap significantly when you are storing large strings or blobs.
– offheap_objects moves the entire cell off heap, leaving only the NativeCell reference containing a pointer to the native (off-heap) data. This makes it effective for small values like ints or uuids as well, at the cost of having to copy it back on-heap temporarily when reading from it.
Для меня остаются актуальными вопросы за что отвечает DirectBuffer и как он работает, ведь сначала говорится “moves the cell name and value to DirectBuffer”, а потом добавляется “the values are still “live” Java buffers”. На Stackoverflow я получил ответ 17 по этому поводу:
A DirectBuffer is memory area allocated directly using JNA (probably using malloc), it can not can not contain “live” Java objects, they must be serialized. Yet this memory is not managed by the JVM hence ignored by GC.
Прямое отношение к типу кэша Memtable имеют параметры memtable_heap_space_in_mb 18 и memtable_offheap_space_in_mb 19, которые отвечают за размеры буфера при on-heap и off-heap размещении соответственно.
Последний новый параметр – memtable_cleanup_threshold 20. Задает отношение занятого несбрасываемого размера Memtable к общему допустимому размеру. Высокое значение будет означать частый сброс данных в небольшие по объему SSTable.
В некоторых источниках можно встретить несколько устаревшую информацию о memtable. Ниже некоторые рассуждения, которые могут быть актуальны для обладателей предыдущих версий Cassandra, однако не стоит все принимать на веру, во многих случаях это лишь мои собственные размышления.
Известно, что для одного колоночного семейства может существовать несколько Memtable – одна текущая, остальные ожидающие процесса сброса на диск 21:
multiple memtables may exist for a single column family, one current and the rest waiting to be flushed.
Однако остается вопрос что значит “полная Memtable” (full memtable) и почему рекомендуется устанавливать значение параметра memtable_flush_queue_size к максимальному количеству индексов для одного колоночного семейства 22:
The number of full memtables to allow pending flush (memtables waiting for a write thread). At a minimum, set to the maximum number of indexes created on a single table.
Возможно имеет место следующий алгоритм: когда одиночный сегмент commit log достигает своего максимального объема, создается новый файл commit log (один для всех CF) на жестком диске и новые Memtable (по одной для каждого CF) в оперативной памяти. Одновременно старый commit log помечается битом 0 (то есть ожидает операции flush). Если будет достигнут один из максимальных пределов – commitlog_total_space_in_mb для commit log и memtable_total_space_in_mb для memtable, самые старшие полные memtable начинают помещаться в очередь (memtable flush queue) и после их сброса на диск в SSTable, удаляются (точно также и соответствующие им commit log). Это лишь мое предположение на основе той информации, которую мне удалось найти в сети.
Notes:
- MemtableSSTable ↩
- The write path to compaction ↩
- Skip list ↩
- Class ConcurrentSkipListMap ↩
- Обзор java.util.concurrent.* ↩
- Список с пропусками ↩
- Еще раз про skiplist… ↩
- A Deep Dive Into Understanding Apache Cassandra ↩
- Cassandra 2.0.1, 2.0.2, and a quick peek at 2.0.3 ↩
- Tuning Java resources ↩
- memtable_flush_writers ↩
- memtable_flush_queue_size ↩
- Cassandra High Availability by Robbie Strickland ↩
- What’s new in Cassandra 2.1 ↩
- memtable_allocation_type ↩
- Off-heap memtables in Cassandra 2.1 ↩
- Memtable understanding ↩
- memtable_heap_space_in_mb ↩
- memtable_offheap_space_in_mb ↩
- memtable_cleanup_threshold ↩
- Cassandra: The Definitive Guide ↩
- memtable_flush_queue_size ↩