
![]() После предыдущих частей я подошел к основному компоненту архитектуры Cassandra — SSTable, который выполняет функцию долговременного хранилища полезных данных. В этой статье я постараюсь рассмотреть основные элементы хранилища рассказать об используемых алгоритмах и дать как можно больше ссылок на полезные и наиболее актуальны источники информации.
После предыдущих частей я подошел к основному компоненту архитектуры Cassandra — SSTable, который выполняет функцию долговременного хранилища полезных данных. В этой статье я постараюсь рассмотреть основные элементы хранилища рассказать об используемых алгоритмах и дать как можно больше ссылок на полезные и наиболее актуальны источники информации.
При переполнении Memtable или Commit log будет инициирован сброс данных из Memtable, которые находятся в оперативной памяти, на жесткий диск. Данные будут помещены в структуру, которая называется Sorted Strings Table (сокр. SSTable) и обладает следующими свойствами:
- неизменность (immutable);
- существуют на каждое колоночное семейство;
- для каждой SSTable создается индекс раздела (partition index), сводка раздела (partition summary), bloom-фильтр;
Каждое свойство и некоторые другие нюансы будут рассмотрены ниже отдельно. А пока дополним упрощенную схему из предыдущих статей. Напомню, что её оригинал взят из официальной документации 1.
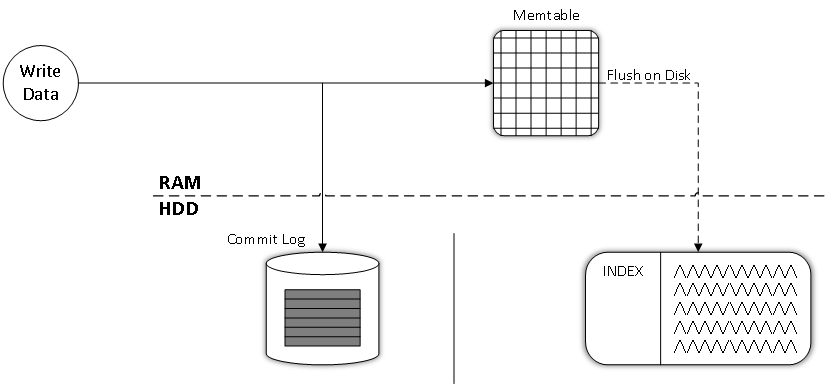
Несмотря на то, что SSTable располагаются на жестком диске, они все же хранят некоторые компоненты в оперативной памяти для ускорения доступа. Отметим все элементы на подробной схеме, заглянув тем самым немного вперед:

SSTable представляет из себя достаточно сложную структуру, состоящую из различных компонентов. На рисунке выше показаны лишь часть из них. Каждому компоненту соответствует определенный файл на жестком диске. Все файлы имеют один и тот же формат имени: <пространство_ключей>-<колоночное_семейство>-[tmp_marker]-<версия>-<поколение>-<компонент>. Если с именами пространства ключей и колоночного семейства все понятно, то другие значения вызывают вопросы, рассмотрим их подробнее:
- Присутствие маркера [tmp_marker] означает, что файл находится в процессе создания;
- <версия> отражает значение текущей версии формата SSTable. К сожалению, в документации Cassandra нет описания версий формата SSTable и приходится довольствоваться лишь неофициальными источниками 2, на текущий момент для Cassandra 2.1 версия формата SSTable — jb;
- <поколение> увеличивается на 1 с созданием каждой новой SSTable, фактически оно отражает количество созданных SSTable для определенного колоночного семейства;
- <компонент> содержит название того или иного компонента. Возможно 7 различных вариантов:
| Имя компонента | Расширение файла | Назначение |
| CompressionInfo | .db | Содержит информацию для расшифровки потока данных. |
| Data | .db | Содержит полезные данные — наборы записей и соответствующие им колонки в упорядоченном состоянии. |
| Filter | .db | Данные bloom-фильтра, основная задача которого ответить на вопрос существует ли определенная запись в данной SSTable или нет. |
| Index | .db | Структура, содержащая ключи записей и соответствующие им значения смещений в файле данных. |
| Statistics | .db | Содержит статистические данные — объемы записей, количество колонок и др. |
| Summary | .db | Некоторое подобие сокращенного Index-файла — по 1 на каждые 128 строчек по умолчанию (см. ниже «Сводка раздела») |
| TOC | .txt | Содержит список компонентов для определенной SSTable |
Все компоненты постоянно хранятся на жестком диске в папке, имя которой аналогично имени пространству ключей, однако некоторые (bloom-фильтр, сводка раздела) из них подгружаются в оперативную память для ускорения доступа, что и отражено на расширенной иллюстрации. Ниже можно увидеть более подробную информацию о некоторых компонентах.
Содержание
Основные компоненты
Индекс раздела 3
Представляет из себя своего рода карту данных определенной SSTable, которая содержит все ключи записей и необходимое смещение относительно начала файла данных. Учитывая упорядоченную по ключам записей структуру SSTable и последовательный порядок записи на диск, можно говорить об ускорении доступа к данным при использовании индекса раздела. Это положительно сказывается на скорости ответа на клиентские запросы чтения. Помимо ключей и их смещений содержатся также и другие данные, однако в официальных источниках отсутствует подробное описание структуры индексов раздела. На основании имеющейся информации можно предположить существование структуры:
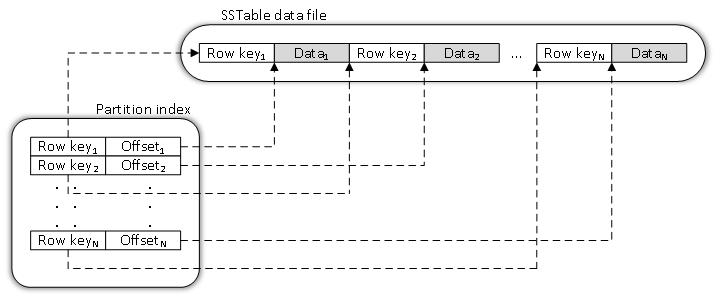
Однако на разных источниках встречаются и другие 4 описания.
Сводка раздела 5
Предназначена для ускорения поиска смещения необходимой записи внутри файла данных SSTable. Представляет из себя множество записей, каждая из которых указывает на записи индекса раздела с шагом в 128. Графически можно представить следующим образом:

Может возникнуть вопрос почему не сделать указатель на каждую запись или просто не обращаться к индексу раздела сразу. Все дело в том, что индекс раздела располагается на жестком диске, а сводка индекса — в оперативной памяти и единица объема выходит значительно дороже. Учитывая тот факт, что записей могут быть миллиарды, разместить ключи записи и указатели на них полностью в оперативной памяти становится проблематично, а без сводки раздела пришлось бы считывать последовательно весь индекс для поиска необходимого значения. В таком случае использование одного указателя в оперативной памяти на каждые 128 записей индекса выглядит очень логично.
Управление шагом кэширования сводки индекса осуществляется изменением параметров min_index_interval (128 по умолчанию) и max_index_interval (2048 по умолчанию), которые были введены в версии Cassandra 2.1 6. До этого был лишь параметр index_interval. Параметры могут быть определены для каждого колоночного семейства 7. Максимальное значение интервала может быть достигнуто лишь при условии редкого характера операций чтения данных колоночного семейства, а также полного заполнения кэша сводки индекса 8. В свою очередь размер кэша сводки индексов задается параметром index_summary_capacity_in_mb 9, который по умолчанию равен 5% от динамической памяти Java.
Поскольку внутри каждой записи может быть множество колонок (вплость до 2 млрд. в некоторых частных случаях), необходимо регулировать степень их детализации. Это становится возможным благодаря параметру column_index_size_in_kb 10, который по умолчанию равен 64КБ на запись.
Управление кэшем индексов осуществляется параметрами reduce_cache_capacity_to 11 и reduce_cache_sizes_at 12. Несмотря на возможность изменения, лучше все же оставить данные параметры со значениями по умолчанию.
Bloom-фильтр 13
Имея сотни, а может быть и тысячи SSTable как быстро ответить на вопрос в какой из них искать нужную запись? Можно последовательно перебирать файлы индексов раздела, но это очень сильно нагрузит дисковую подсистему, пусть даже это будет проходить через сводки разделов, располагающихся в оперативной памяти. Есть более гибкое решение, которое может однозначно предупреждать о 100% отсутствии нужной записи в той или иной SSTable. Решение заключается в использовании вероятностной структуры данных под названием bloom-фильтр (по фамилии создателя). «Вероятностная» означает, что полученный ответ не может быть на 100% достоверным, в нашем случае мы задаем вопрос «Имеется ли запись А в SSTable 1» и получаем один из возможных ответов — «Точно нет» или «Скорее всего да». То есть во втором случае мы имеем некоторую вероятность нахождения записи в определенной SSTable. В случае с Cassandra значение вероятности можно гибко регулировать и итоговая вероятность отсутствия записи при положительном ответе составит не больше нескольких процентов или ещё меньше.
Для понимания работы компонента более подробного объяснения в принципе не нужно, к тому же в официальной документации все ограничивается достаточно скупыми объяснениями и рекомендациями 14. Однако я все же постараюсь более подробно объяснить как работает bloom-фильтр.
Допустим мы имеем массив битов некоторой длины и 2 разные хэш-функции. Значение хэш-функций для имени Lena (в нашем случае имя — это ключ записи) будет равно 45 для первой хэш-функции и 92 для второй соответственно. В массиве битов, который изначально состоит только из 0, переводим соответствующие по счету биты в значение 1. То же самое выполняем для имени Masha, но только получаем 73 для первой хэш-функции и 23 для второй. Теперь имеем массив битов, в котором позиции 45, 92, 73 и 23 установлены в 1. Далее сбрасываем данные в SSTable, в которой в итоге будем иметь всего две записи — Lena и Masha, назовем её «SSTable 1».
Сценарий работы: получаем на входе ключ записи со значением Egor (для наглядности я все также использую имена как ключи записей). Имея SSTable 1, нам надо ответить на вопрос «В SSTable 1 есть запись Egor?». Для этого вычисляем для ключа записи Egor хэш-функции и на выходе получаем, например, значения 48 для первой и 76 для второй хэш-функции. Теперь просматриваем наш массив битов «bloom-фильтра» и проверяем в какое значение установлены соответствующие биты. В итоге видим, что биты под номерами 48 и 76 установлены в 0 и таким образом получаем ответ: «В SSTable 1 точно нет записи Egor». В итоге не обращаясь ни к индексам раздела, ни к сводке индекса мы получили нужный ответ. При проверке ключа записи Lena мы получим значения 45 и 92 для первой и второй хэш-функции и проверив соответствующие биты массива увидим, что они установлены в 1, таким образом получаем ответ, что скорее всего запись с ключом Lena присутствует в SSTable 1.
Почему «скорее всего»? Дело в том, что присутствует некоторая вероятность того, что у полностью отличающегося от присутствующих значения ключа записи, мы можем получить значения всех хэш-функций, которые будут равны значениям существующих ключей записей. В итоге будет ложное срабатывание. Наглядный пример из Википедии 15:

Иллюстрация, подробно показывающая пример работы bloom-фильтра, все также из Википедии 16:
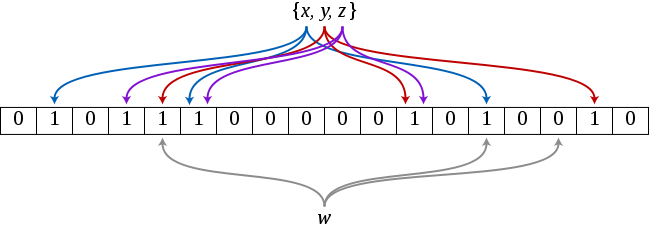
An example of a Bloom filter, representing the set { x, y, z }. The colored arrows show the positions in the bit array that each set element is mapped to. The element w is not in the set { x, y, z }, because it hashes to one bit-array position containing 0. For this figure, m = 18 and k = 3.
С bloom-фильтром на этом все, переходим к компоненту SSTable, ради которого собственно и нужны все механизмы, рассмотренные выше.
Файл данных SSTable 17
Основной компонент SSTable, содержащий полезные данные — записи и соответствующие им колонки в упорядоченном по ключу виде.
Одно из основных свойств SSTable — неизменяемость, то есть будучи однажды созданы, все свое время они находятся в неизменном состоянии (то есть реально доступны только для чтения). Поскольку SSTable создаются по мере полного заполнения Memtable, размер кэша Memtable напрямую влияет на интенсивность создания SSTable и на их объем. Если с процессом записи новых данных все достаточно просто и понятно, то с обновлением существующих все значительно интереснее: фактически одна и та же запись может существовать в нескольких значениях и чтобы найти самое свежее, нужно их всех сравнить. Конечно же сравнение происходит по значению Timestamp у нужных колонок. Если в процессе обновления записи были изменены только определенные колонки, то вполне возможно, что актуальные значения всех колонок одной записи будут собраны абсолютно из разных SSTable. Этим объясняется на первый взгляд удивительная особенность Cassandra, связанная с тем, что скорость чтения может быть значительно ниже записи.
Похожим образом, но в некоторой степени сложнее, обстоят дела с удалением записей. Как уже было сказано, SSTable представляют из себя неизменяемые единицы и таким образом удалить запись (или колонку) из них не получится — получится создать новую колонку и присвоить ей значение null (значение Timestamp у колонки должно быть самым свежим). Таким образом Cassandra будет идентифицировать эту колонку как удаленную и не будет возвращать её значение при клиентском запросе. Колонка с таким значением называется надгробием (tombstone). Теоретически массовые операции удаления колонок, которые ещё к тому же были ранее много раз изменены, значительно ухудшают производительность операций чтения, ведь накапливается огромное количество мусора. Крайне желательно минимизировать количество операций DELETE в вашей модели данных, но если это не выходит, то не нужно сильно беспокоиться, поскольку существует механизм слияния множества SSTable в одну и называется он сжатием (compaction).
От рассмотрения других компонентов, таких как CompressionInfo и Statistics, в рамках этой статьи я откажусь в виду недостаточного количества информации в свободном доступе, вспомогательном характере их основного назначения, а также во избежание элементарной перегрузки информацией и без того большой статьи. Всю необходимую дополнительную литературу, использованную при написании статьи, рекомендую брать из сносок.
Notes:
- Storing data on disk in SSTables ↩
- Cassandra SSTable Format Version Numbers ↩
- partition index ↩
- Cassandra: SSTable Storage Format ↩
- partition summary ↩
- DataStax Community release notes ↩
- Table properties ↩
- min_index_interval and max_index_interval ↩
- index_summary_capacity_in_mb ↩
- column_index_size_in_kb ↩
- reduce_cache_capacity_to ↩
- reduce_cache_sizes_at ↩
- Bloom filter ↩
- Tuning Bloom filters ↩
- Hash function ↩
- Bloom filter WikipediA ↩
- SSTable ↩