
![]() Процесс чтения и записи данных в реальности происходит значительно сложнее, чем это можно представить при первом рассмотрении вопроса. Имея дело с распределенной СУБД, есть смысл как можно глубже представлять себе эти процессы. В серии статей «Apache Cassandra. Запись данных» я собираюсь пролить свет на компоненты, использующиеся при записи данных, а также разобраться в принципе их работы.
Процесс чтения и записи данных в реальности происходит значительно сложнее, чем это можно представить при первом рассмотрении вопроса. Имея дело с распределенной СУБД, есть смысл как можно глубже представлять себе эти процессы. В серии статей «Apache Cassandra. Запись данных» я собираюсь пролить свет на компоненты, использующиеся при записи данных, а также разобраться в принципе их работы.
Первым делом данные записываются в Commit Log, а уже затем в оперативную память в Memtables 1:
Cassandra writes are first written to a commit log (for durability), and then to an in-memory table structure called a memtable.
Commit Log представляет из себя структуру данных, которая располагается на жестком диске и запоминает (логирует) все операции записи для повышения живучести данных (data durability) при различных сбоях (например потеря питания). Commit Log состоит из одного или нескольких файлов, максимальный объем каждого определяется значением переменной 2:
commitlog_segment_size_in_mb 3 — по умолчанию 32MB. За обслуживание каждого файла отвечает отдельный экземпляр класса CommitLogSegment 4. Файл состоит из цепочек изменений (row mutation) тех или иных строк колоночных семейств. То есть в одном сегменте могут быть цепочки не только различных строк, но и строк из разных колоночных семейств и пространств ключей.
Максимальный размер Commit Log ограничивается параметром:
commitlog_total_space_in_mb — по умолчанию 32MB для 32-х битной версии JVMs 5 и 8192MB для 64-х битной. При превышении порога данные из Memtable сбрасываются на диск в SSTables, после чего из Commit Log соответствующие записи удаляются.
Поскольку отдельных файлов Commit log может быть множество, то при достижении максимального объема текущим файлом, сразу будет создаваться и заполняться данными другой и так пока не будет превышено максимальное значение объема для всего Commit Log. При достижении максимального объема будет инициирован сброс (flush) данных из Memtable в SSTable, после которого будут удалены соответствующие файлы Commit log с устаревшими данными.
Имена файлов сегментов Commit Log имеют следующий формат: Commitlog-<table>-<timestamp>.log. Судя по всему, возраст файла определяется именно по значению Timestamp. Однако это исключительно личные наблюдения, информации по этому вопросу, к сожалению, в свободном доступе найти не удалось.
Commit Log может работать в двух различных режимах:
periodic — Commit Log (расположенный на жестком диске) будет синхронизироваться с кэшем страниц 6 операционной системы каждые 10 секунд по умолчанию (то есть операция fsync 7 будет производиться каждые 10 секунд), при этом подтверждение записи отправляется уже после приема данных в кэш страниц ОС, синхронизации дожидаться не нужно. Время можно регулировать с помощью изменения параметра commitlog_sync_period_in_ms. Недостаток в том, что в пределах этого времени вы можете потерять данные внутри кэша страниц, в случае если все реплики будут безвозвратно утеряны 8;
batch — подтверждение записи данных отправляется только после выполнения синхронизации fsync. Это дает 100% гарантию записи, однако цена надежности — высокие требования к производительности дисковой подсистемы. Перед сбросом данных идет кратковременное ожидание, равное значению commitlog_sync_batch_window_in_ms, по умолчанию 50 миллисекунд (а это на порядки меньше, чем 10 секунд в режиме periodic). Строго рекомендуется иметь отдельный физический диск под Commit Log при использовании этого режима.
Управление режимами работы Commit Log осуществляется с помощью изменения параметра commitlog_sync.
Стоит также упомянуть о параметре, который отвечает за управление размером очереди Commit Log — commitlog_periodic_queue_size. По умолчанию 1024*CPU_core. Изменять параметр рекомендуют при оперировании blob-структурами больших размеров и как минимум согласовывать его с настройками concurrent_writes:
When writing very large blobs, reduce this number. For example, 16 × number_of_cpu_cores works reasonably well for 1MB blobs. This setting should be at least as large as the concurrent_writes setting.
Лучше всего принцип работы записи данных иллюстрируют примеры из официальной документации 9, по аналогии с которыми я изображу схематичный вариант только структуры Commit Log:
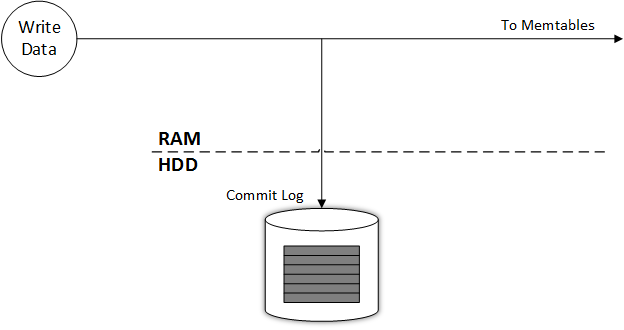
Как видно из рисунка, запись данных начинается с логирования в Commit Log на жесткий диск, затем данные помещаются в Memtables, которая использует оперативную память. Попробуем немного усложнить рисунок, добавив компоненты операционной системы, без понимания функционирования которых представление о работе Commit Log было бы неполным:
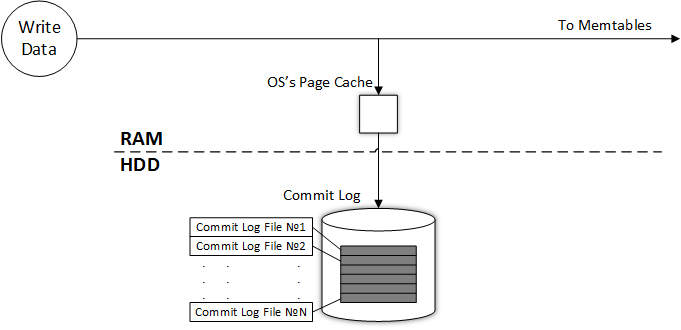
Как уже было сказано выше, page cache операционной системы некоторое время накапливает данные (по умолчанию 10 секунд) изменения файла и потом принудительно (с помощью вызова fsync) фиксирует все изменения. Поскольку кэш страниц располагается в оперативной памяти, всегда есть определенный риск потери этого небольшого объема данных при одновременном аппаратном сбое на всех узлах-носителях реплики, на которую идет запись данных.
На этом анализ структуры Commit Log СУБД Cassandra завершен и я перехожу к рассмотрению следующего компонента — Memtables — в статье Apache Cassandra. Запись данных. Часть 2 — Memtable.
Notes: