
![]() При оперировании данными минимальной структурной единицей является запись. Не набор колонок или единственная колонка, а именно запись. На запись указывает её ключ, уникальный в рамках колоночного семейства (аналог таблицы в реляционной СУБД). Исходя из ключа записи определяется маркер (маркером будет результат хэш-функции, для которой входной параметр — ключ записи), а уже отталкиваясь от значения маркера СУБД понимает на какой узел/узлы нужно поместить всю запись целиком.
При оперировании данными минимальной структурной единицей является запись. Не набор колонок или единственная колонка, а именно запись. На запись указывает её ключ, уникальный в рамках колоночного семейства (аналог таблицы в реляционной СУБД). Исходя из ключа записи определяется маркер (маркером будет результат хэш-функции, для которой входной параметр — ключ записи), а уже отталкиваясь от значения маркера СУБД понимает на какой узел/узлы нужно поместить всю запись целиком.
Partition key
В СУБД Cassandra ключ записи — первичный ключ колоночного семейства. Первичный ключ определяется на этапе инструкции создания колоночного семейства, например 1(нужно сразу оговориться, что синтаксис очень похож на традиционный для реляционных СУБД):
CREATE TABLE object_coordinates (
object_id int PRIMARY KEY,
coordinate text
);
object_coordinates — имя колоночного семейства (таблица с координатами объекта);
object_id — идентификатор объекта;
coordinate — координаты объекта
В примере выше представлен самый простой вариант первичного ключа. В пределах колоночного семейства запись уникально идентифицируется значением идентификатора объекта. Весь первичный ключ в этом примере будет являться ключом раздела (partition key), по которому Cassandra определит на каком узле/узлах будет храниться данная запись. Каждый раз как от одного и того же объекта будут приходить координаты, запись будет обновляться, поскольку идентификатор объекта не изменяется. Таким образом будут храниться только последние координаты объекта.
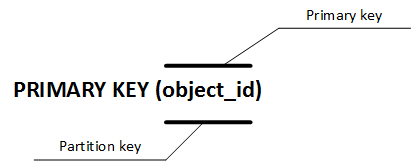
Логическое представление будет выглядеть примерно так:

В поле значения столбца Value будет имя пользователя; Timestamp — метка времени, по которой СУБД определит самую новую запись у всех имеющихся узлов, если данные вдруг будут рассинхронизированы.
А вот пример с реальными данными:
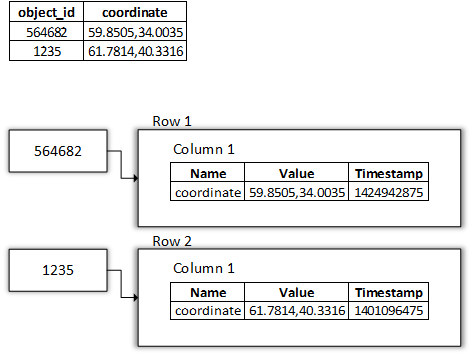
Значение Timestamp выставлено как пример.
Compound primary key & Clustering key
А что если нужно сохранять вообще всю историю координат? С помощью рассмотренного примера это сделать не получится, поскольку старые координаты каждый раз затираются новыми, если конечно же новые координаты поступают. Для реализации возможности хранения всей истории координат нужно несколько усложнить пример:
CREATE TABLE object_coordinates (
object_id int,
time timestamp,
coordinate text,
PRIMARY KEY (object_id, time)
);
Добавим дополнительную колонку time, которая будет хранить время прихода координат, и используем её в primary key. Таким образом мы получили составной первичный ключ (compound primary key). Состоит этот ключ из ключа раздела (partition key) и ключа группировки (clustering key). Ключ раздела всегда является значением до первой запятой, все что идет далее — ключ группировки:
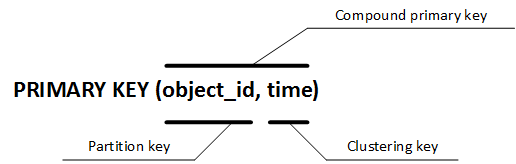
Поскольку теперь первичный ключ будет идентифицироваться двумя полями, то если хотя бы одно из них отличается, то фактически это уже должна быть другая запись. Но на самом деле ситуация будет немного сложнее: если ключ раздела будет у двух записей один и тот же, а ключ группировки отличаться, то это в итоге будет одна большая запись, но состоящая из двух. Лучше всего это объяснить с помощью рисунка:
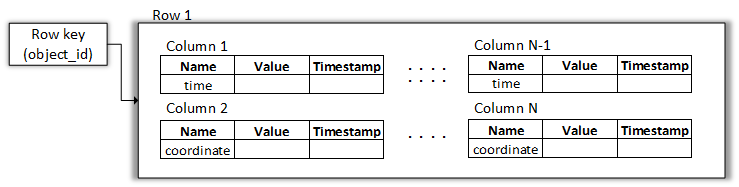
Главное отличие от простого первичного ключа состоит в том, что записи с отличающимися значениями ключа группировки добавляются к существующей записи с идентичным ключом. Записи упорядочены по ключу группировки и по ним может осуществляться поиск. Наш пример в данном случае будет выглядеть так (добавим несколько значений, чтобы иллюстрация была более наглядной):
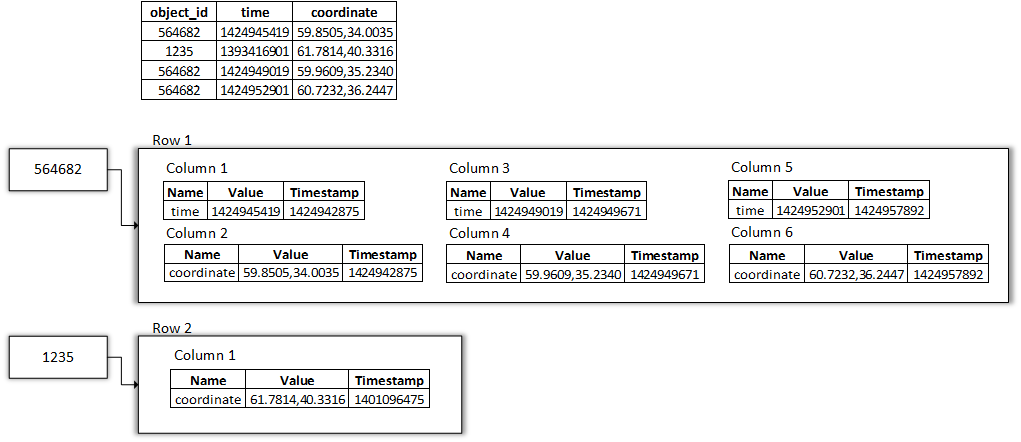
Вторая запись также будет дополняться данными по мере поступления новых координат от объекта с соответствующим идентификатором.
Composite partition key
В предыдущем примере мы добились того, что СУБД будет хранить всю историю изменения координат объекта (правда стоит оговориться, что формат Timestamp хранит данные с точностью до одной секунды, поэтому если у вас за одну секунду успели прийти несколько координат объекта, то они перезатрутся и в базе будет лишь последнее значение за секунду. Однако выявленный недостаток не помешает выполнить основное назначение примера — наглядно продемонстрировать структуру первичных ключей). Однако тут нас ждет один неприятный сюрприз — мы можем наткнуться на ограничение 2 СУБД по максимальному количеству ячеек (rows*columns) в 2 млрд.
Это ограничение ставит под угрозу сохранение всей истории координат объекта, поскольку после достижения предела данные перестанут записываться. Решение есть и оно заключается в использовании комбинированного ключа раздела (composite partition key), суть которого в использовании нескольких колонок для образования ключа раздела. Изменим наш пример соответственным образом:
CREATE TABLE object_coordinates (
object_id int,
date text,
time timestamp,
coordinate text,
PRIMARY KEY ((object_id, date), time)
);
Необходимо добавить дополнительную колонку, в моем случае я выбрал дату, и добавить её в ключ раздела, обозначив скобками. Таким образом, если мы будем иметь различные значения хотя бы одного значения в ключе раздела — object_id или date — то по сути это будет уже другой раздел и для него ограничение в 2 млрд. обнулится, что нам и нужно. Рассмотрим подробнее:
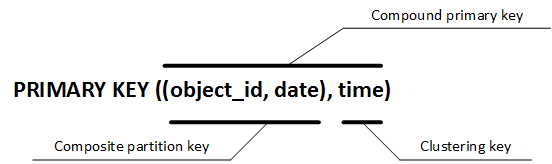
Фактически мы теперь имеем составной первичный ключ с комбинированным ключом раздела и ключом группировки.
Логическое представление данных тоже несколько усложнится:
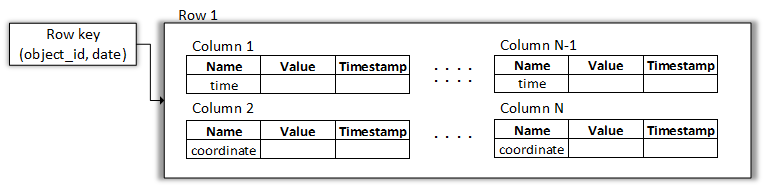
В соответствии с этой логикой наш пример будет выглядеть следующим образом:
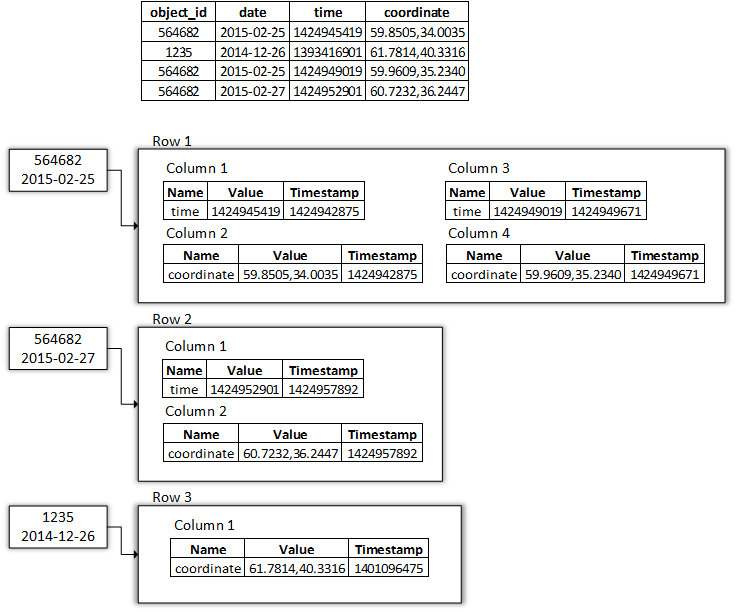
На этом я заканчиваю обзор строения и вариаций первичного ключа в СУБД Cassandra. В сети не так много информации по поводу этого вопроса, но все же встречается ряд обзоров 3 4 (хоть и не из официальных ресурсов), которые неплохо описывают большинство нюансов. Особенно мне помогла статья 5 от Patrick McFadin.
Notes: