
В ZABBIX имеется возможность создания с нуля пользовательских правил низкоуровневого обнаружения и это крайне полезная функциональность для тех администраторов, кто хочет мониторить всех и вся. Именно с этим функционалом вы можете возвращать наборы каких угодно данных – будь то перечень дисков на сервере, список баз данных или что-то другое.
Процесс создания шаблонов мониторинга на основе LLD я разобью на две статьи. В первой (то есть в этой) расскажу конкретно про обнаружение, а во второй про все остальное.
Если вам интересна тематика ZABBIX, рекомендую обратиться к основной статье – Система мониторинга ZABBIX, в ней вы найдете дополнительную информацию.
Содержание
Низкоуровневое обнаружение в ZABBIX: правила LLD
В официальной документации эта тема 1 рассмотрена подробно, но на мой взгляд примеры слишком узкие (штатное обнаружение файловых систем, snmp OID’ов и сетевых интерфейсов) и обсуждение вопроса начинается совсем не с того конца. По поводу пользовательских правил обнаружения присутствует лишь небольшая “приписка” в самом конце с примером скрипта на perl (!).
Мне же хочется рассмотреть вопрос значительно шире, но в то же время на конкретных примерах. Я расскажу об LLD на основе задачи анализа данных производительности дисковой подсистемы Linux-серверов. Метрики производительности буду получать утилитой iostat (пакет sysstat). Пример вывода данных:
 Вы же можете анализировать вывод любой другой программы.
Вы же можете анализировать вывод любой другой программы.
Что это?
Для тех, кто ещё не знает о чем идет речь, небольшое пояснение на основе простого примера:
у вас есть сервер, на сервере один жесткий диск. Вам нужно отслеживать набор метрик этого диска. Вы без труда создаете шаблон, наполняете его ключами данных, триггерами и прочими элементами и ставите на мониторинг. Далее вам нужно мониторить второй сервер, на котором два диска (разумеется с разными именами). Перед вами встает задача написать новый или дополнить существующий шаблон ещё одним диском с точно такими же метриками. А что, если потом у вас появится сервер с 10 дисками или более?
Правила обнаружения элегантно решают подобные задачи, самостоятельно определяя список отслеживаемых объектов с заранее установленными одинаковыми метриками для каждого.
Правила обнаружения
Для создания правила обнаружения необходимо зайти в шаблон мониторинга (или создать новый, если его ещё нет) – Правила обнаружения – Создать правило обнаружения:
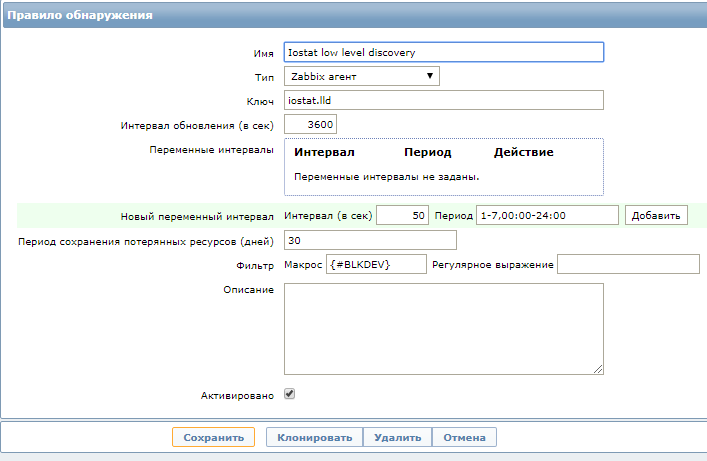 Подавляющее большинство параметров произвольные и вы можете выбрать для них любые значения, но все же я поясню некоторые моменты:
Подавляющее большинство параметров произвольные и вы можете выбрать для них любые значения, но все же я поясню некоторые моменты:
- Имя – любое на ваш вкус;
- Тип – только Zabbix агент;
- Ключ – выберите любой, но потом вы должны использовать это же имя ключа в конфигурации агента Zabbix;
- Интервал обновлений – не выставляйте слишком маленький интервал, ведь аппаратная конфигурация сервера обычно меняется редко. Для отладки можете использовать значение в 60 сек., чтобы не ждать слишком долго;
- Фильтр – имя макроса, которое будет использоваться для извлечения имен блочных устройств (актуально для моего примера. У вас это может быть что-то другое, например имена сетевых интерфейсов). Макрос должен быть заключен в {#}, в имени допускается использование символов A-Z , 0-9 , _;
Нажимайте Сохранить и на этом этапе работы на стороне сервера Zabbix завершены, в следующих статьях мы сюда ещё вернемся.
Набор данных
Агент должен возвращать серверу набор отслеживаемых элементов в формате json (список блочных устройств, если опираться на мой пример). Это главное и единственное требование. Каким образом вы это реализуете уже не так важно. Данные в человекочитаемом виде могут выглядеть так:
|
1 2 3 4 5 6 7 |
{ "data":[ {"{#BLKDEV}":"name_1"}, {"{#BLKDEV}":"name_2"}, {"{#BLKDEV}":"etc..."} ] } |
Вы можете возвратить их с помощью отдельного скрипта (пример скрипта на bash, который возвращает список дисков с Linux-сервера в json, анализируя вывод утилиты iostat):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/bin/bash array="$(iostat -d | awk '/Device:/ {while(getline==1 && $1!="") {print $1}}')" comma="" printf '%s' '{"data":[' while IFS= read -r line ; do printf '%s' "$comma{\"{#BLKDEV}\":\"$line\"}" comma="," done <<< "$array" printf '%s' ']}' |
Результат выполнения будет примерно таким (без форматирования):
|
1 |
{"data":[{"{#BLKDEV}":"sda"},{"{#BLKDEV}":"dm-0"},{"{#BLKDEV}":"dm-1"}]} |
Либо вы можете вытащить данные всего одной строчкой (например с помощью awk):
|
1 |
iostat -d | awk '/Device:/ {{printf "{\"data\":["}while(getline==1) if($1!=""){printf comma"{\"{#BLKDEV}\":\""$1"\"}";comma=","} {printf "]}"}}' |
В обоих случаях вывод одинаковый.
Конфигурация агента
Следующий этап – настроить агента ZABBIX, чтобы он возвращал серверу нужные данные. Сделать это нужно через конфигурационный файл агента (для Debian – /etc/zabbix/zabbix_agentd.conf). В самый конец добавляем строчку с пользовательским параметром:
|
1 |
UserParameter=iostat.lld,/path/to/script.sh |
Это если для получения данных используете скрипт. Если же нужно выполнить одну строчку кода, то это можно сделать сразу внутри параметра:
|
1 |
UserParameter=iostat.lld,iostat -d | awk '/Device:/ {{printf "{\"data\":["}while(getline==1) if($1!=""){printf comma"{\"{#BLKDEV}\":\""$1"\"}";comma=","} {printf "]}"}}' |
Сохраняем изменения, выходим, перезапускаем агента командой:
|
1 |
service zabbix-agent restart |
Работы на стороне агента пока что завершены.
Проверка
Самое время все проверить и сделать это лучше всего с сервера Zabbix командой:
|
1 |
zabbix_get -s 192.168.0.4 -p 10050 -k "iostat.lld" |
Где 192.168.0.4 – адрес сервера с агентом Zabbix, состояние которого необходимо отслеживать. Команда должна возвратить список дисков в формате json как в примере в предыдущей главе. Если это произошло, значит все прошло успешно. Если же нет, то разбирайтесь что где сделали неправильно.