
![]() Реляционные базы данных, в которых основой является табличная структура, подавляющему большинству читателей будут знакомы. Однако если говорить о нетрадиционных концепциях хранения данных, например «ключ-значение», а не таблица, многие с трудом представляют себе о чем идет речь и в каком виде будут храниться данные в этом случае. Я не был исключением.
Реляционные базы данных, в которых основой является табличная структура, подавляющему большинству читателей будут знакомы. Однако если говорить о нетрадиционных концепциях хранения данных, например «ключ-значение», а не таблица, многие с трудом представляют себе о чем идет речь и в каком виде будут храниться данные в этом случае. Я не был исключением.
Имея опыт работы с реляционными СУБД, будь то опыт администрирования или разработки, достаточно трудно сразу переключить мышление на другой характер — изучая нереляционные хранилища все ещё продолжаешь мыслить реляционными понятиями. Для тех, кто ещё полностью не перешел на оперирование нереляционными категориями, я постараюсь описать модель данных СУБД Apache Cassandra — неограниченно масштабируемой нереляционной бесплатной СУБД с открытым исходным кодом.
Описание модели данных начнем с самого простого и дойдем до наивысших по иерархии структур.
Колонка 1 (Column) — наипростейшая единица данных, состоит из трех полей с полезной информацией в теле каждого — имя (Name), значение (Value), метка времени (Timestamp).
![]()
Метка времени Timestamp необходима для поддержания в актуальном состоянии значения колонки, поскольку теоретически может возникнуть ситуация, когда на разных узлах кластера значения одной и той же колонки будут разными. В таком случае будет использоваться значение колонки, которая имеет самую свежую метку времени, а неактуальные данные на других узлах обновятся.
Запись 2 (Row) — набор колонок с данными. В пределах колоночного семейства уникально идентифицируется ключом записи (Row key), фактически являющимся чем-то вроде первичного ключа.

Записи не дробятся на колонки, а хранятся целиком на определенных узлах. Чтобы понять на каком узле будет храниться запись, используется значение (маркер) хэш-функции от ключа записи — за определенные диапазоны маркеров отвечают определенные узлы в кластере. Этот механизм я подробно расписал в одной 3 из моих статей.
Стоит отметить, что логическое представление записей, рассмотренное выше, может несколько отличаться в различных ситуациях. На это влияет каким образом определен первичный ключ для колоночного семейства. Этой темы, однако, я не планирую касаться, поскольку она подробно рассмотрена в статье Apache Cassandra. Первичные ключи и особенности хранения записей.
Колоночное семейство 4 (Column family) — контейнер для колонок, содержащих полезные данные. В SQL-хранилищах ближайшим аналогом будет таблица.
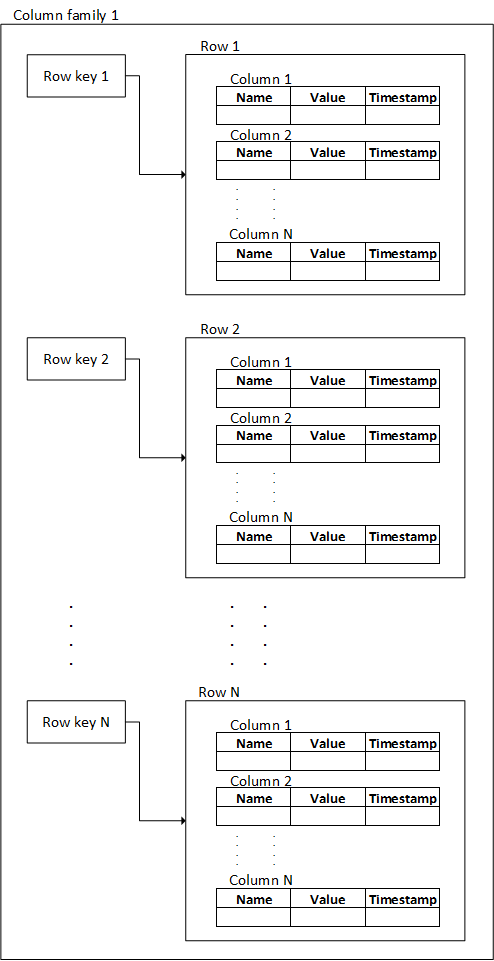
Как и таблиц, колоночных семейств может быть множество.
Пространство ключей 5 (Keyspace) — аналог схемы 6 базы данных у реляционных СУБД.
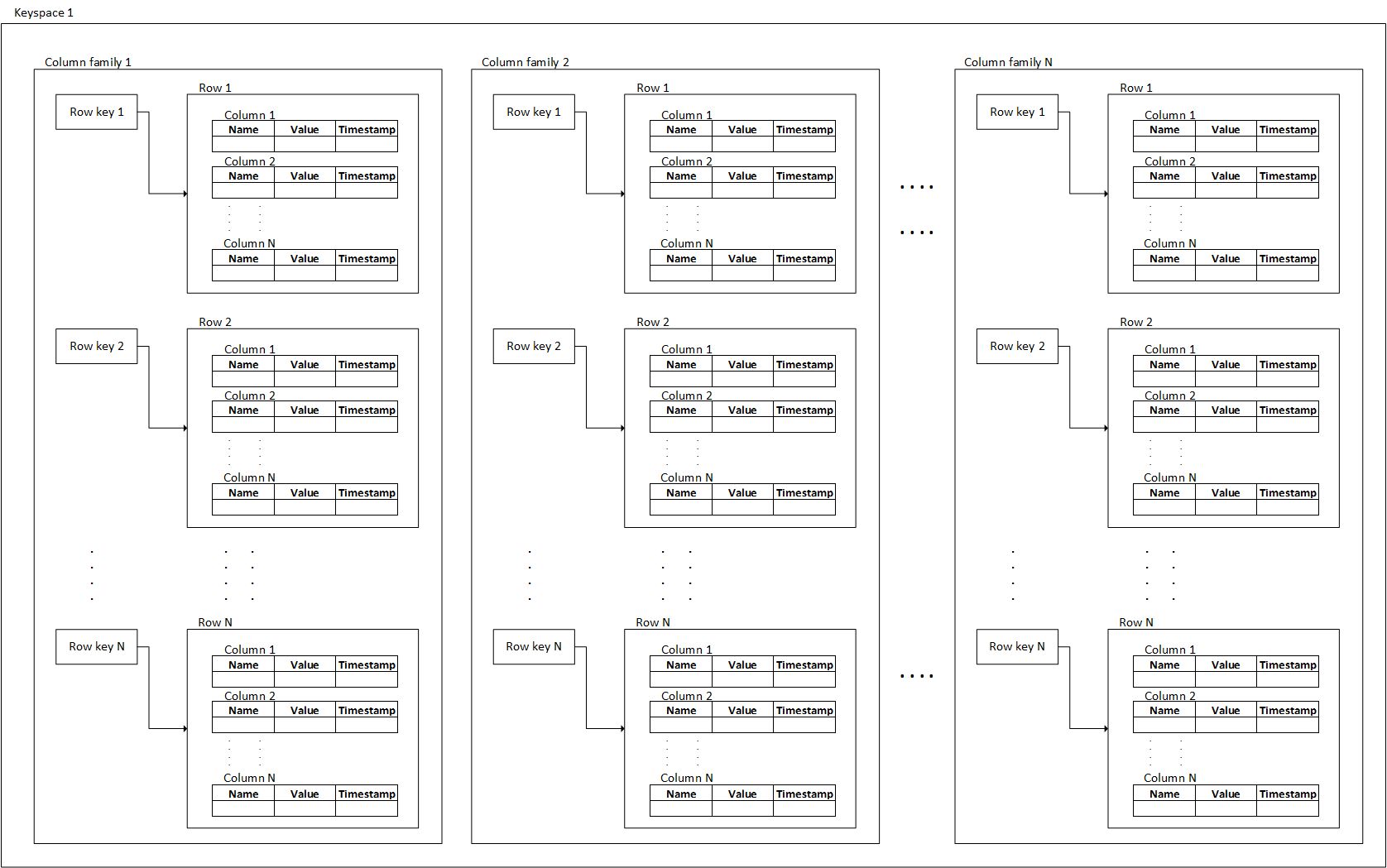
Как в любой СУБД может быть множество баз данных, точно также и пространств ключей может быть несколько.
В ближайшем рассмотрении информации выше достаточно, чтобы сформировать определенное представление о модели данных СУБД Cassandra.
Notes: