
 Счетчик Processor Queue Length является одной из самых важных метрик центрального процессора и показывает сколько запросов в данный момент находится в очереди к ЦП. Я не упоминал о нем в своих недавних статьях (Счетчики производительности процессора и Анализ счетчиков производительности CPU), ведь в них главным образом идет речь о счетчиках из двух групп — Процессор (Processor) и Сведения о процессоре (Processor Information), а Processor Queue Length (Длина очереди процессора) принадлежит группе Система (System).
Счетчик Processor Queue Length является одной из самых важных метрик центрального процессора и показывает сколько запросов в данный момент находится в очереди к ЦП. Я не упоминал о нем в своих недавних статьях (Счетчики производительности процессора и Анализ счетчиков производительности CPU), ведь в них главным образом идет речь о счетчиках из двух групп — Процессор (Processor) и Сведения о процессоре (Processor Information), а Processor Queue Length (Длина очереди процессора) принадлежит группе Система (System).
Если вам интересны счетчики производительности Windows, рекомендую обратиться к основной статье тематики — Счетчики производительности.
Processor Queue Length
Показания счетчика действительно очень важны для поиска проблем с производительностью процессора. Постоянное наличие большой очереди запросов к ЦП явно свидетельствует о том, что процессор не справляется с обработкой данных и является узким местом. Тем не менее до конца непонятно какие показания счетчика считаются явно плохими и указывающими на проблему, а какие являются нормой. В интернете вы не найдете исчерпывающей информации по этому вопросу, большинство ресурсов ограничивается простым описанием принципа работы счетчика, который и так очевиден.
На основе реальных данных попробуем разобраться что можно считать плохим или хорошим.
О чем реально может говорить большое количество запросов в очереди к ЦП в конкретный момент времени?
- Что ЦП как минимум задействован в работе и не простаивает. Это очевидный момент;
- Что ЦП по каким-либо причинам не смог переварить запросы в короткий промежуток времени и в связи с этим образовалась очередь;
- Какое-то приложение\оборудование генерирует запросы к ЦП;
- Какое-то приложение\драйверы имеют не слишком оптимизированный код и в связи с этим ЦП проводит много времени в ожидании между потоками.
Первый пункт в комментариях не нуждается, а вот второй нужно рассмотреть более детально. Обратимся к графику загрузки CPU реального сервера.
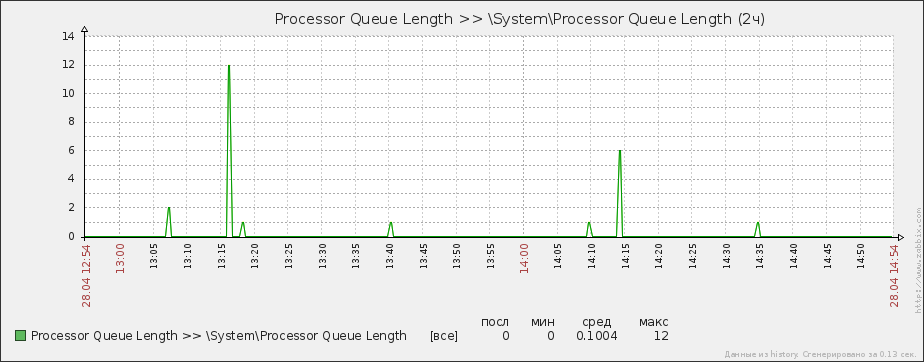
Вверху вы можете увидеть график длины очереди процессора на сервере Exchange 2013. Вылезают очень неприятные пики, в то время как по общеизвестным рекомендациям не должны встречаться ситуации, когда очередь составляет больше двукратного количества центральных процессоров на сервере (у меня один ЦП, значит максимальная очередь — 2, в разных источниках критической называют длину очереди 10 для одного CPU). Но теперь обратим внимание на загрузку ЦП, а именно на счетчик % Processor Time:
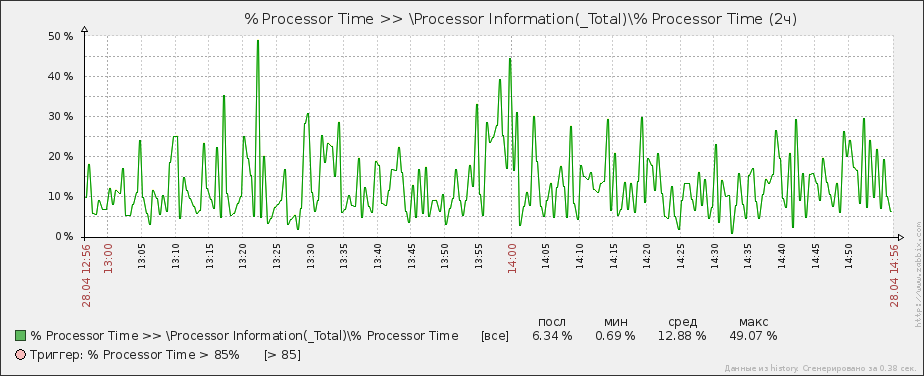
Как вы можете заметить, на графике даже пиковые значения загрузки ЦП не достигают и 50%, а это практически идеально подобранная производительность ЦП для тех задач, которые решает сервер — одновременно нет лишних простоев, но есть и запас производительности для периодов повышенной загрузки. В итоге делаем вывод:
Краткосрочные высокие значения очереди CPU являются нормой
Для примера рассмотрим ещё один график, но уже другого сервера — сервера СУБД MS SQL.
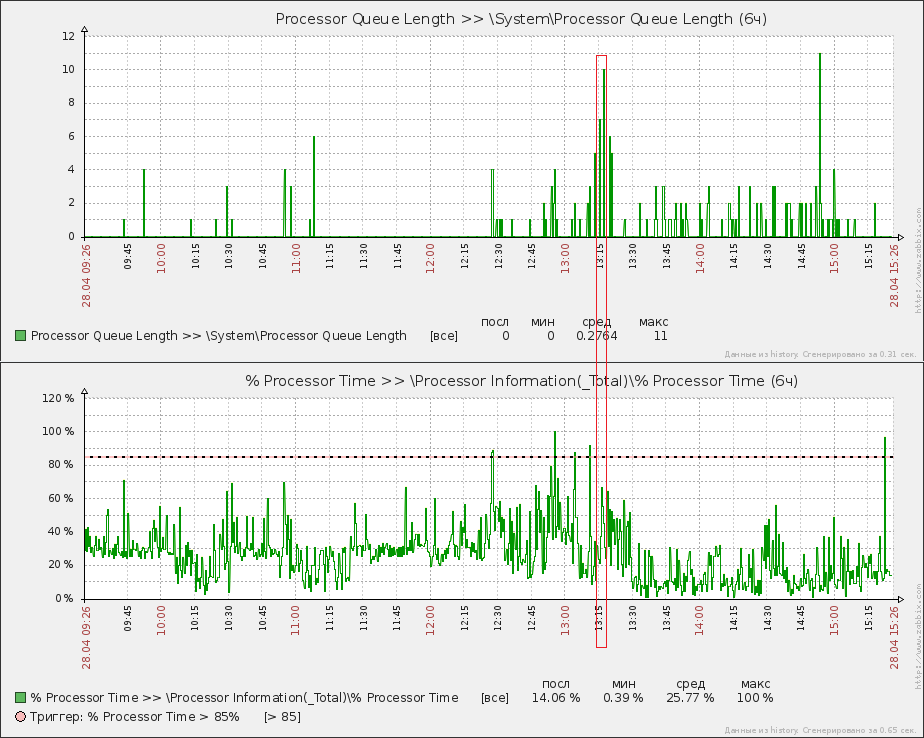
Пиковые значения очереди тут встречаются уже значительно чаще, но, надо отметить, они не совпадают с периодами максимальной загрузки ЦП (показательный случай выделен красной рамкой), а наоборот встречаются в моменты сравнительно низкой загрузки. В периоды своей низкой загрузки ЦП значительно чаще переходит в состояния пониженного энергопотребления и из этого можно сделать вывод, что, возможно, это тоже является причиной возникновения очередей.
То есть, как бы это парадоксально ни звучало, но графики говорят о том, что очередь может возникать во время простоев ЦП и причиной этому являются переходы В и выходы Из состояний пониженного энергопотребления. В этом случае анализируйте показания счетчиков % C1 Time, % C2 Time, % C3 Time, C1 Transitions/sec, C2 Transitions/sec, C3 Transitions/sec. Отключайте на уровне bios сам функционал перехода.
Хорошо, два примера выше иллюстрируют нормальное поведение ЦП, но что тогда считать проблемой? Есть у меня пример и на этот случай:
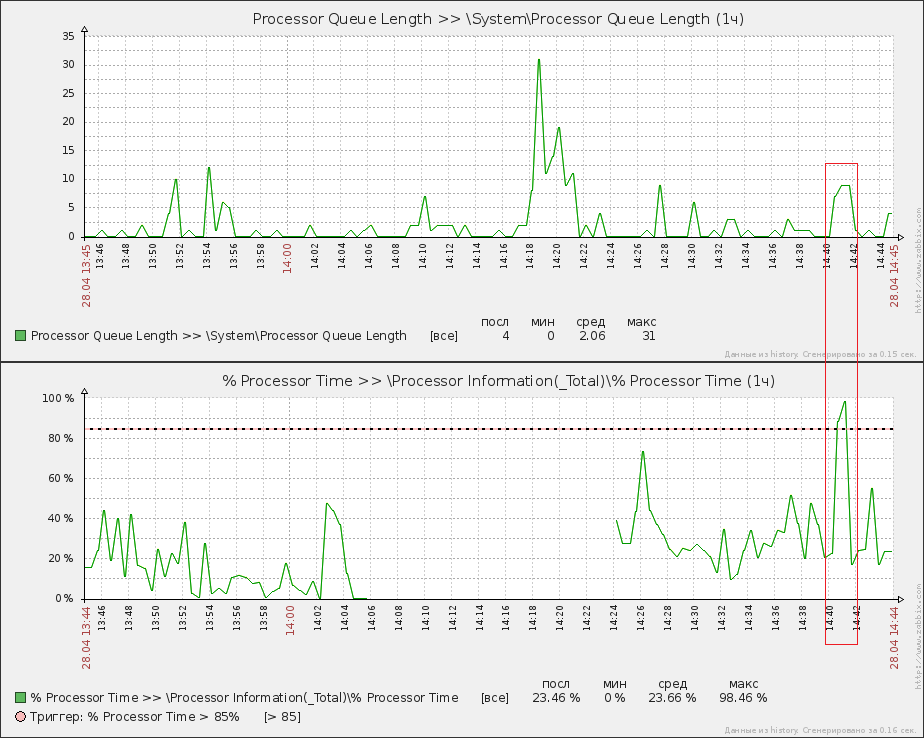
Это график одного из серверов, который выполняет требовательные к CPU задачи и на графиках явно видны ситуации, когда процессору не хватало мощности для обработки всего объема. В какой-то момент времени начались даже проблемы с доступностью данных счетчика % Processor Time — на нижнем графике есть достаточно большой пробел. По данным на графиках косвенно можно сделать вывод, что загрузка ЦП в момент очереди выше 10 была больше критической. Это подтверждает момент, когда очередь процессора стабильно находилась на уровне 6-8 единиц и % Processor Time показал загрузку >85% (на графике период выделен красной рамкой). Делаем вывод: проблемой является состояние, когда очередь ЦП находится стабильно выше 2. Ключевое слово стабильно.
Стоит отметить, что в каждом конкретном случае критическими могут быть разные значения. Главным критерием должна быть отзывчивость приложения. Например если сервер 1С стал регулярно выдавать средние значения очереди в 3 единицы, но пользователи при этом не заметили ухудшений вообще, то можно оставить все как есть. Если же пользователи стали резко жаловаться на тормоза программы и вы действительно заметили увеличение времени реакции ПО при выполнении обычных задач, вам нужно увеличить процессорную мощность.
Моя рекомендация:
Обращать внимание на Processor Queue Length > 2 в течение 5 минут. Критическим будет значение очереди >10 в течение 5 минут
На этом все, делитесь своим опытом в комментариях.
