
![]() Поскольку Cassandra – СУБД с распределенной системой хранения данных, одним из ключевых элементов архитектуры является механизм обеспечения распределенности хранения, основные понятия которого я постараюсь описать в этой статье.
Поскольку Cassandra – СУБД с распределенной системой хранения данных, одним из ключевых элементов архитектуры является механизм обеспечения распределенности хранения, основные понятия которого я постараюсь описать в этой статье.
Физические понятия
Под физическими понятиями я буду подразумевать прежде всего структурные элементы архитектуры, которые однозначно можно выделить в самостоятельные единицы на том или ином уровне. В этом разделе я не планирую затрагивать понятия, которые относятся к механизмам оперирования данными.
Узел 1 (Node)
Базовый компонент всей архитектуры. Именно на узлах хранятся данные. Теоретически в инфраструктуре может существовать лишь один 2 узел, но тогда ни о какой отказоустойчивости и распределенности хранения говорить не приходится. На практике рекомендуется, чтобы было такое количество узлов, которое удовлетворяет потребностям в производительности с небольшим запасом (в 20-30%), на случай выхода из строя одного или нескольких узлов, а также для удовлетворения будущих потребностей в расширении.
В элементарном виде узел можно представить следующим образом:
В реальной обстановке узел – это физический или виртуальный сервер с операционной системой (например, Debian) и установленной на неё СУБД Cassandra, имеющий доступ к сети для взаимодействия с клиентами.
Стойка (Rack)
Виртуальный объект, в буквальном смысле представляющий из себя стойку серверов внутри центра обработки данных. Введен для минимизации рисков физических сбоев (проблемы с питанием, охлаждением или проблемы с сетью) внутри одной стойки.
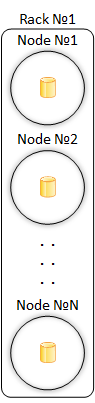
Хоть и понятие стойки чисто виртуальное, на практике рекомендуется придерживаться существующего физического расположения узлов и по возможности разносить их по разным стойкам.
Центр обработки данных 3 (Data Center)
Ни что иное, как логическое объединение стоек. Кластер (см. ниже) может существовать как в рамках одного, так и нескольких центров обработки данных. Это значительно влияет на репликацию данных.
Обобщенное представление кластера:
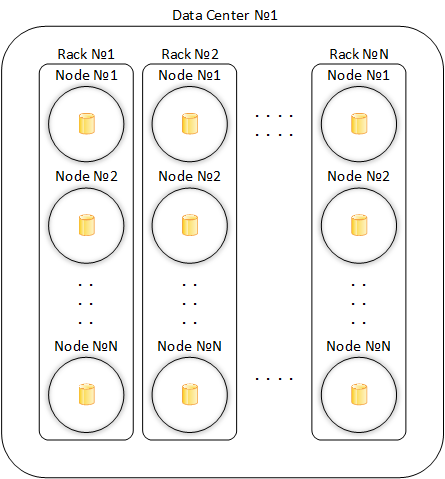
Учитывая минимально двойное резервирование, необходимо иметь два центра обработки данных, в каждом из которых будет по две стойки, по одному узлу в стойке. Таким образом мы получаем минимальное количество узлов, необходимое для реализации приемлемого уровня отказоустойчивости – 4 штуки.
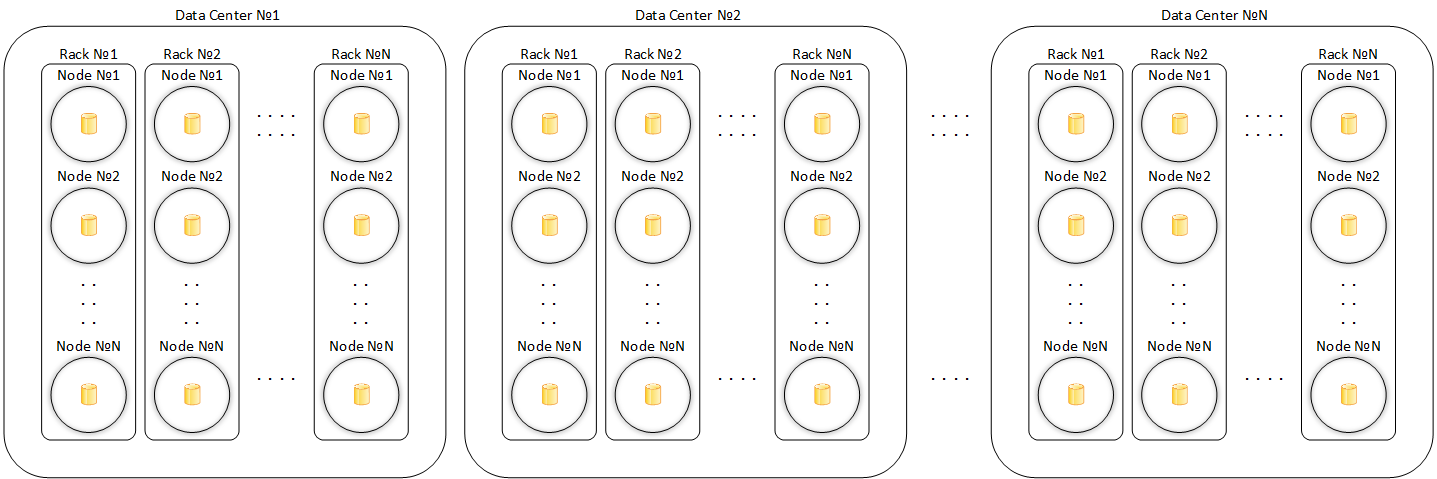
Кластер 4 (Cluster)
Набор узлов, который образует полное и замкнутое кольцо маркеров (читай ниже).
Логические понятия
Рассмотрев выше физические элементы архитектуры СУБД Cassandra, пришло время заглянуть на более низкий уровень взаимодействия и попытаться описать основные понятия при оперировании данными. Надо сразу оговориться, что речь о логической структуре данных внутри БД идти не будет, поскольку это относится несколько к другой области – модели данных.
Раздел 5 (Partition)
Представляет из себя структурную единицу данных, состоящую из одной или более записи (row). Разные разделы хранятся на разных узлах (или разных наборах узлов). Cassandra самостоятельно определяет узел, на котором будет храниться тот или иной раздел с помощью определенного механизма, дословно называемого распределитель (partitioner). По сути распределитель – хэш-функция 6, входным параметром для которой является ключ записи (row key); на выходе получаем значение этой хэш-функции, называемое маркером 7 (token). Поскольку хэш-функция гарантирует получение из входных данных произвольного размера результат в виде данных фиксированного размера (это её основная особенность), то можно не беспокоиться о размере или типе входного параметра. Кроме того, если вы будете друг за другом вычислять хэш-функцию для одного и того же входного параметра, то на выходе всегда будете получать один и тот же маркер, что гарантирует всегда точное определение узла с нужными данными как в процессе чтения, так и в процессе записи (например, при обновлении данных). Распределитель по умолчанию – Murmur3Partitioner 8, однако в предыдущих версиях (до 1.2) использовался RandomPartitioner 9 и другие (см. соответств. разделы 10 11 документации).
В официальной документации 12 достаточно подробно расписан принцип работы разделения данных:
Data Distribution in the Ring
In Cassandra, the total amount of data managed by the cluster is represented as a ring. The ring is divided into ranges equal to the number of nodes, with each node being responsible for one or more ranges of the data. Before a node can join the ring, it must be assigned a token. The token value determines the node’s position in the ring and its range of data. Column family data is partitioned across the nodes based on the row key. To determine the node where the first replica of a row will live, the ring is walked clockwise until it locates the node with a token value greater than that of the row key. Each node is responsible for the region of the ring between itself (inclusive) and its predecessor (exclusive). With the nodes sorted in token order, the last node is considered the predecessor of the first node; hence the ring representation.
Для лучшего понимания, перевод:
“В Cassandra итоговый объем данных, обслуживаемых кластером, представляется в виде кольца. Кольцо разделено на диапазоны, количество которых равно количеству узлов, каждый узел отвечает за один или более диапазона данных. Перед присоединением узла к кластеру, ему должен быть назначен маркер. Значение маркера определяет позицию узла в кольце и диапазон данных, за который он будет отвечать. Данные колоночного семейства разделены по узлам, основываясь на ключе записи. Чтобы определить узел, где будет “жить” первый экземпляр записи, необходимо пройти по кольцу по часовой стрелке пока не встретится узел с маркером, который больше, чем маркер ключа записи. Каждый узел ответственен за участок кольца между самим собой (включая свой маркер) и своим предшественником (исключая его маркер). Узлы отсортированы в порядке возрастания маркеров, последнему узлу предшествует первый и таким образом образуется представление в виде кольца”.
Пример, идеально иллюстрирующий весь этот механизм, есть в официальных видеороликах 13 и я позволю себе его позаимствовать:

В каждом центре обработки данных одинаковым цветом обозначены узлы, которые хранят одинаковые реплики. На кольце ниже также соответствующим цветом обозначены диапазоны маркеров, за которые отвечают определенные узлы.
Реплика (Replica)
Чтобы не потерять данные при выходе из строя одного или более узла, необходимо обеспечить некоторую избыточность, то есть хранить копии (реплики) одних и тех же разделов на разных узлах одновременно. Количество хранимых копий данных определяется коэффициентом копирования или, другими словами, фактором репликации 14 (replication factor). Разумеется копии данных хранятся на разных узлах. Все копии одних и тех же данных абсолютно равнозначны, не существует первичных или вторичных реплик.
Процесс распределения копий называется репликацией данных (data replication).
Механизм распространения реплик называется стратегией репликации (replication strategy), существует две стратегии:
- SimpleStrategy. Может использоваться только в рамках одиночного центра обработки данных. Принцип работы: вычисляется маркер ключа записи и далее, согласно известному алгоритму (см. выше), определяется узел, ответственный за хранение этой записи. Все остальные реплики помещаются на следующие по часовой стрелке узлы без учета топологии.
- NetworkTopologyStrategy. Учитывает количество центров обработки данных. Принцип работы: в отличие от простой стратегии, при обходе по часовой стрелке выбирается не первый попавшийся узел, а первый попавшийся узел из другой стойки. Учитывая уровень согласованности данных (см. ниже), можно гибко управлять максимально допустимым количеством вышедших из строя узлов для сохранения возможности чтения и записи или только для сохранения возможности чтения данных.
Важным механизмом распространения реплик является уровень согласованности 15 (consistency level), который отвечает за обеспечение степени согласованности данных в репликах. Уровень согласованности определяется для чтения и записи данных:
- Уровень согласованности за запись данных определяет от скольки узлов должны быть получены подтверждения о записи, чтобы клиенту было отправлено подтверждение об успешной операции записи данных.
- Уровень согласованности на чтение данных определяет от скольки узлов должен быть получен ответ на запрос чтения от клиента, чтобы отправить данные.
Процесс взаимодействия
Для обмена информацией о расположении и состоянии друг друга узлы кластера используют одноранговый 16 протокол под названием Gossip 17 18. Ежесекундно каждый узел отправляет максимум трем другим узлам информацию о самом себе, а также информацию о других узлах (полученную по тому же Gossip), которая ему известна. Согласованность информации поддерживается с помощью версий сообщений, старые данные затираются. Очень важно, чтобы узлы были осведомлены о состоянии друг друга, ведь если какие-либо из них выйдут из строя, необходимо предотвратить маршрутизацию к ним клиентских запросов. Конечно о выходе узла в кластере станет известно не сразу из-за некоторых задержек в обмене информации, однако этот нюанс взаимодействия также можно регулировать, таким образом определяя чувствительность 19 к сбоям.
Процесс инициализации 20 21 всего кластера начинается с запуска так называемых узлов-источников (seed node), которые содержат в себе информацию о других узлах, данные о топологии кольца. Необходимо иметь как минимум один узел-источник на центр обработки данных, но рекомендуется не меньше двух, все также в угоду отказоустойчивости. Далее должны быть запущены обычные узлы, которые обратятся за необходимой информацией к узлам-источникам. После этого процесс взаимодействия осуществляется обычным образом.
Notes:
- Architecture in brief ↩
- Cassandra FAQ: Can I Start With a Single Node? ↩
- data center ↩
- Introduction to Cassandra Clusters ↩
- Cassandra Essentials Tutorials: Understanding Partitioning and Replication in Cassandra ↩
- Hash function ↩
- Generating Tokens ↩
- Murmur3Partitioner ↩
- RandomPartitioner ↩
- Partitioners ↩
- Partitioners – Cassandra Wiki ↩
- About Data Partitioning in Cassandra ↩
- Introducing Cassandra’s node-based architecture ↩
- Data replication ↩
- Configuring data consistency ↩
- Peer-to-Peer Protocol (P2PP) ↩
- Gossip protocol ↩
- Internode communications (gossip) ↩
- Failure detection and recovery ↩
- Initializing a multiple node cluster (multiple data centers) ↩
- Initializing a multiple node cluster (single data center) ↩